What Is Data Cleaning and Why Does It Matter?
Effective data cleaning is a vital part of the data analytics process. But what is it, why is it important, and how do you do it?
Good data hygiene is so important for business. For starters, it’s good practice to keep on top of your data, ensuring that it’s accurate and up-to-date. However, data cleaning is also a vital part of the data analytics process. If your data has inconsistencies or errors, you can bet that your results will be flawed, too. And when you’re making business decisions based on those insights, it doesn’t take a genius to figure out what might go wrong!
In a field like marketing, bad insights can mean wasting money on poorly targeted campaigns. In a field like healthcare or the sciences, it can quite literally mean the difference between life and death. In this article, I’ll explore exactly what data cleaning is and why it’s so vital to get it right. We’ll also provide an overview of the key steps you should take when cleaning your data.
Why not get familiar with data cleaning and the rest of the data analytics process in our free 5-day data short course ?
We’ll answer the following questions:
- What is data cleaning?
- Why is data cleaning important?
- How do you clean data?
- What are some of the most useful data cleaning tools?

1. What is data cleaning?
Data cleaning (sometimes also known as data cleansing or data wrangling) is an important early step in the data analytics process .
This crucial exercise, which involves preparing and validating data, usually takes place before your core analysis. Data cleaning is not just a case of removing erroneous data, although that’s often part of it. The majority of work goes into detecting rogue data and (wherever possible) correcting it.
What is rogue data?
‘Rogue data’ includes things like incomplete, inaccurate, irrelevant, corrupt or incorrectly formatted data. The process also involves deduplicating, or ‘deduping’. This effectively means merging or removing identical data points.
Why is it important to correct rogue data?
The answer is straightforward enough: if you don’t, they’ll impact the results of your analysis.
Since data analysis is commonly used to inform business decisions, results need to be accurate. In this case, it might seem safer simply to remove rogue or incomplete data. But this poses problems, too: an incomplete dataset will also impact the results of your analysis. That’s why one of the main aims of data cleaning is to keep as much of a dataset intact as possible. This helps improve the reliability of your insights.
Data cleaning is not only important for data analysis. It’s also important for general business housekeeping (or ‘data governance’). The sources of big data are dynamic and constantly changing. Regularly maintaining databases, therefore, helps you keep on top of things. This has several additional benefits, which we’ll cover in the next section.
Want to try your hand at cleaning a dataset? You may be interested in this introductory tutorial to data cleaning, hosted by Dr. Humera Noor Minhas.
2. Why is data cleaning important?
A common refrain you’ll hear in the world of data analytics is: ‘garbage in, garbage out’. This maxim, so often used by data analysts, even has its own acronym… GIGO. But what does it mean?
Essentially, GIGO means that if the quality of your data is sub-par, then the results of any analysis using those data will also be flawed. Even if you follow every other step of the data analytics process to the letter, if your data is a mess, it won’t make a difference.
For this reason, the importance of properly cleaning data can’t be overstated. It’s like creating a foundation for a building: do it right and you can build something strong and long-lasting. Do it wrong, and your building will soon collapse. This mindset is why good data analysts will spend anywhere from 60-80% of their time carrying out data cleaning activities. Beyond data analytics, good data hygiene has several other benefits. Let’s look at those now.
Key benefits of data cleaning
As we’ve covered, data analysis requires effectively cleaned data to produce accurate and trustworthy insights. But clean data has a range of other benefits, too:
- Staying organized: Today’s businesses collect lots of information from clients, customers, product users, and so on. These details include everything from addresses and phone numbers to bank details and more. Cleaning this data regularly means keeping it tidy. It can then be stored more effectively and securely.
- Avoiding mistakes: Dirty data doesn’t just cause problems for data analytics. It also affects daily operations. For instance, marketing teams usually have a customer database. If that database is in good order, they’ll have access to helpful, accurate information. If it’s a mess, mistakes are bound to happen, such as using the wrong name in personalized mail outs .
- Improving productivity: Regularly cleaning and updating data means rogue information is quickly purged. This saves teams from having to wade through old databases or documents to find what they’re looking for.
- Avoiding unnecessary costs: Making business decisions with bad data can lead to expensive mistakes. But bad data can incur costs in other ways too. Simple things, like processing errors, can quickly snowball into bigger problems. Regularly checking data allows you to detect blips sooner. This gives you a chance to correct them before they require a more time-consuming (and costly) fix.
- Improved mapping: Increasingly, organizations are looking to improve their internal data infrastructures. For this, they often hire data analysts to carry out data modeling and to build new applications. Having clean data from the start makes it far easier to collate and map, meaning that a solid data hygiene plan is a sensible measure.
Data quality
Key to data cleaning is the concept of data quality. Data quality measures the objective and subjective suitability of any dataset for its intended purpose.
There are a number of characteristics that affect the quality of data including accuracy, completeness, consistency, timeliness, validity, and uniqueness. You can learn more about data quality in this full article .
3. How to clean your data (step-by-step)
So far, we’ve covered what data cleaning is and why it’s important. In this section, we’ll explore the practical aspects of effective data cleaning. Since there are multiple approaches you can take for completing each of these tasks, we’ll focus instead on the high-level activities.
Step 1: Get rid of unwanted observations
The first stage in any data cleaning process is to remove the observations (or data points) you don’t want. This includes irrelevant observations, i.e. those that don’t fit the problem you’re looking to solve.
For instance, if we were running an analysis on vegetarian eating habits, we could remove any meat-related observations from our data set. This step of the process also involves removing duplicate data. Duplicate data commonly occurs when you combine multiple datasets, scrape data online, or receive it from third-party sources.
Step 2: Fix structural errors
Structural errors usually emerge as a result of poor data housekeeping. They include things like typos and inconsistent capitalization, which often occur during manual data entry.
Let’s say you have a dataset covering the properties of different metals. ‘Iron’ (uppercase) and ‘iron’ (lowercase) may appear as separate classes (or categories). Ensuring that capitalization is consistent makes that data much cleaner and easier to use. You should also check for mislabeled categories.
For instance, ‘Iron’ and ‘Fe’ (iron’s chemical symbol) might be labeled as separate classes, even though they’re the same. Other things to look out for are the use of underscores, dashes, and other rogue punctuation!
Step 3: Standardize your data
Standardizing your data is closely related to fixing structural errors, but it takes it a step further. Correcting typos is important, but you also need to ensure that every cell type follows the same rules.
For instance, you should decide whether values should be all lowercase or all uppercase, and keep this consistent throughout your dataset. Standardizing also means ensuring that things like numerical data use the same unit of measurement.
As an example, combining miles and kilometers in the same dataset will cause problems. Even dates have different conventions, with the US putting the month before the day, and Europe putting the day before the month. Keep your eyes peeled; you’ll be surprised what slips through.
Step 4: Remove unwanted outliers
Outliers are data points that dramatically differ from others in the set. They can cause problems with certain types of data models and analysis.
For instance, while decision tree algorithms are generally accepted to be quite robust to outliers, outliers can easily skew a linear regression model. While outliers can affect the results of an analysis, you should always approach removing them with caution.
Only remove an outlier if you can prove that it is erroneous, e.g. if it is obviously due to incorrect data entry, or if it doesn’t match a comparison ‘gold standard’ dataset.
Step 5: Fix contradictory data errors
Contradictory (or cross-set) data errors are another common problem to look out for. Contradictory errors are where you have a full record containing inconsistent or incompatible data.
An example could be a log of athlete racing times. If the column showing the total amount of time spent running isn’t equal to the sum of each racetime, you’ve got a cross-set error.
Another example might be a pupil’s grade score being associated with a field that only allows options for ‘pass’ and ‘fail’, or an employee’s taxes being greater than their total salary.
Step 6: Type conversion and syntax errors
Once you’ve tackled other inconsistencies, the content of your spreadsheet or dataset might look good to go.
However, you need to check that everything is in order behind the scenes, too. Type conversion refers to the categories of data that you have in your dataset. A simple example is that numbers are numerical data, whereas currency uses a currency value. You should ensure that numbers are appropriately stored as numerical data, text as text input, dates as objects, and so on. I
n case you missed any part of Step 2, you should also remove syntax errors/white space (erroneous gaps before, in the middle of, or between words).
Step 7: Deal with missing data
When data is missing, what do you do? There are three common approaches to this problem.
The first is to remove the entries associated with the missing data. The second is to impute (or guess) the missing data , based on other, similar data. In most cases, however, both of these options negatively impact your dataset in other ways. Removing data often means losing other important information. Guessing data might reinforce existing patterns, which could be wrong.
The third option (and often the best one) is to flag the data as missing . To do this, ensure that empty fields have the same value, e.g. ‘missing’ or ‘0’ (if it’s a numerical field). Then, when you carry out your analysis, you’ll at least be taking into account that data is missing, which in itself can be informative.
Step 8: Validate your dataset
Once you’ve cleaned your dataset, the final step is to validate it. Validating data means checking that the process of making corrections, deduping, standardizing (and so on) is complete.
This often involves using scripts that check whether or not the dataset agrees with validation rules (or ‘check routines’) that you have predefined. You can also carry out validation against existing, ‘gold standard’ datasets.
This all sounds a bit technical, but all you really need to know at this stage is that validation means checking the data is ready for analysis. If there are still errors (which there usually will be) you’ll need to go back and fix them…there’s a reason why data analysts spend so much of their time cleaning data!
4. Data cleaning tools
Now we’ve covered the steps of the data cleaning process, it’s clear that this is not a manual task. So, what tools might help? The answer depends on factors like the data you’re working with and the systems you’re using. But here are some baseline tools to get to grips with.
Microsoft Excel
MS Excel has been a staple of computing since its launch in 1985. Love it or loathe it, it remains a popular data-cleaning tool to this day. Excel comes with many inbuilt functions to automate the data cleaning process, from deduping to replacing numbers and text, shaping columns and rows, or combining data from multiple cells . It’s also relatively easy to learn, making it the first port of call for most new data analysts.
Programming languages
Often, data cleaning is carried out using scripts that automate the process. This is essentially what Excel can do, using pre-existing functions. However, carrying out specific batch processing (running tasks without end-user interaction) on large, complex datasets often means writing scripts yourself.
This is usually done with programming languages like Python , Ruby, SQL , or—if you’re a real coding whizz—R (which is more complex, but also more versatile). While more experienced data analysts may code these scripts from scratch, many ready-made libraries exist. Python, in particular, has a tonne of data cleaning libraries that can speed up the process for you, such as Pandas and NumPy .
Visualizations
Using data visualizations can be a great way of spotting errors in your dataset. For instance, a bar plot is excellent for visualizing unique values and might help you spot a category that has been labeled in multiple different ways (like our earlier example of ‘Iron’ and ‘Fe’). Likewise, scatter graphs can help spot outliers so that you can investigate them more closely (and remove them if needed).
Proprietary software
Many companies are cashing in on the data analytics boom with proprietary software. Much of this software is aimed at making data cleaning more straightforward for non-data-savvy users. Since there are tonnes of applications out there (many of which are tailored to different industries and tasks) we won’t list them here. But we encourage you to go and see what’s available. To get you started, play around with some of the free, open-source tools. Popular ones include OpenRefine and Trifacta .
You’ll find a more thorough comparison of some of the best data cleaning tools in this guide .
Final thoughts
Data cleaning is probably the most important part of the data analytics process. Good data hygiene isn’t just about data analytics, though; it’s good practice to maintain and regularly update your data anyway. Clean data is a core tenet of data analytics and the field of data science more generally.
In this post, we’ve learned that:
- Clean data is hugely important for data analytics: Using dirty data will lead to flawed insights. As the saying goes: ‘Garbage in, garbage out.’
- Data cleaning is time-consuming: With great importance comes great time investment. Data analysts spend anywhere from 60-80% of their time cleaning data.
- Data cleaning is a complex process: Data cleaning means removing unwanted observations, outliers, fixing structural errors, standardizing, dealing with missing information, and validating your results. This is not a quick or manual task!
- There are tools out there to help you: Fear not, tools like MS Excel and programming languages like Python are there to help you clean your data. There are also many proprietary software tools available.
Why not try your hand at data analytics with our free, five-day data analytics short course ? Alternatively, read the following to find out more:
- What are the different types of data analysis?
- Quantitative vs. qualitative data: What’s the difference?
- The 7 most useful data analytics methods and techniques

- New Zealand
- United Kingdom
What Is Data Cleaning in the Context of Data Science?

Stay Informed With Our Weekly Newsletter
Receive crucial updates on the ever-evolving landscape of technology and innovation.
By clicking 'Sign Up', I acknowledge that my information will be used in accordance with the Institute of Data's Privacy Policy .
Data cleaning, also known as data cleansing or scrubbing, is a crucial process in data science. It involves identifying and correcting errors, inconsistencies, and inaccuracies in datasets.
It aims to improve data quality, ensuring it is accurate, reliable, and suitable for analysis.
Understanding the concept of data cleaning

Data cleaning is an integral part of the data science workflow.
At its core, it helps to ensure that the data used for analysis is reliable and appropriate for the intended purpose.
The role of data cleaning in data science
Data cleaning plays a pivotal role in data science as it directly impacts the accuracy of the analysis and the insights derived from it.
By eliminating errors and inconsistencies, it helps to ensure that the conclusions drawn from the data are valid and reliable.
Key terms and definitions in data cleaning
- Data error : Refers to any mistake, inaccuracy, or inconsistency in the dataset.
- Data inconsistency : occurs when different parts of the dataset conflict with each other.
- Data anomaly : This represents an observation that significantly deviates from the expected behavior of the dataset.
By being aware of the types of errors and inconsistencies that can occur, data scientists can develop strategies to detect and rectify them, ensuring the reliability and integrity of the data.
The importance of data cleaning in data science

It involves removing duplicate entries, handling missing values, standardizing formats, and resolving discrepancies.
This meticulous process is crucial for maintaining data integrity and ensuring reliable results.
Ensuring accuracy in data analysis
Data analysis is heavily reliant on the quality of the data being used.
If errors or inconsistencies are present in the dataset, it can lead to incorrect conclusions and misleading insights.
By detecting and addressing outliers, data cleaning ensures that the analysis is not skewed by these unusual data points, resulting in more accurate and meaningful insights.
Enhancing the quality of data
High-quality data is crucial for any data-driven project.
Eliminating errors and inconsistencies helps enhance the dataset’s quality, making it more suitable for analysis.
Clean data can lead to more accurate models, improved decision-making, and better overall outcomes.
It involves transforming all dates into a consistent format, ensuring uniformity and ease of analysis, and handling missing values common in real-world datasets.
The process
Identifying and removing errors.
The first step is to identify and remove errors from the dataset.
Dealing with missing or incomplete data
Data analysis is necessary to have complete data.
Data cleaning involves strategies to handle this issue, such as imputation techniques or excluding incomplete records.
The goal is to ensure the dataset is as complete as possible without introducing bias or inaccuracies.
Tools and techniques for data cleaning
Popular software.
Several software options can assist with data cleaning, including open-source solutions like OpenRefine and commercial software such as Trifacta or SAS Data Integration Studio.
These tools provide features like data profiling, string manipulation, and error detection, simplifying the process.
Manual vs automated data cleaning
The process of cleaning data can be performed manually or through automated processes.
Manual cleaning involves human intervention to identify and correct errors, while automated cleaning utilizes algorithms and scripts to automate the process.
The choice between manual and automated data cleaning depends on factors such as the complexity of the data and the available resources.
Challenges and solutions in cleaning data

Common obstacles in the process
One of the main challenges in cleaning data is dealing with large and complex datasets.
The sheer volume of data can make it difficult to identify errors or inconsistencies.
Additionally, data from multiple sources may have different formats or structures, requiring careful integration and transformation.
Best practices for effective data cleaning
To overcome these challenges, data scientists should follow best practices when cleaning data.
Some tips include:
- Document the process to keep track of changes made to the dataset.
- Perform exploratory data analysis to gain insights into the dataset before cleaning it.
- Use validation techniques to ensure data accuracy after the cleaning process.
- Regularly review and update data cleaning procedures as new issues arise.
Cleaning data is an essential step in the data science workflow that should not be overlooked.
By carefully cleaning and preparing the data, data scientists can ensure the accuracy and reliability of their analyses, leading to better insights and decisions.
Embracing data cleaning as an integral part of the data science process enables organizations to unlock the full potential of their data and derive meaningful and actionable information.
Considering embarking on a data science journey?
By choosing the Institute of Data as your learning partner, you’ll be equipped with the skills needed in this highly sought-after field of tech.
Want to learn more? Contact our local team for a free career consultation today.

Follow us on social media to stay up to date with the latest tech news
Stay connected with Institute of Data

Iterating Into Artificial Intelligence: Sid’s Path from HR to Data Science & AI

From Curiosity to Cybersecurity: Maria Kim’s Path to Protecting the Digital World

Mastering Cybersecurity: Ruramai’s Inspiring Journey from Law to Digital Defense

From Passion to Pursuing a New Career: Neil Kripal’s Driven Journey into Software Engineering

From Teaching to Data Science: Eamon’s Journey of Passion and Persistence
© Institute of Data. All rights reserved.
Copy Link to Clipboard
This website may not work correctly because your browser is out of date. Please update your browser .
Data cleaning

Data cleaning involves the detection and removal (or correction) of errors and inconsistencies in a data set or database due to data corruption or inaccurate entry.
Incomplete, inaccurate or irrelevant data is identified and then either replaced, modified or deleted.
Incorrect or inconsistent data can create a number of problems that lead to the drawing of false conclusions. Therefore data cleaning can be an important element in some data analysis situations. However, data cleaning is not without risks and problems including the loss of important information or valid data.
There are a large variety of tools available that can be used to support data cleaning. Additionally, m any statistical programs have data validation built-in, which can pick up some errors automatically, for example, non-valid variable codes.
Advice for using this method
- Back up your data before starting your data cleaning process.
- Create a list of all variables, variable labels and variable codes.
- Decide which variables are crucial to the analysis and must have values for the responses to be complete. Often, survey responses will come back with missing data for certain questions and variables. If this appears on a crucial variable, the data from that survey will not be useful.
- Something like gender will have in most cases the possible codes of 1 = male, 2 = female, 0 = missing, and so in this case a code of 12 would be an error
- Other errors might include missing data values
- A frequency test can help to identify errors
- Outliers can hide or create statistical significance and are important to identify
- Creating a bar graph or similar is one way to quickly identify outliers
- Cross-tabulating pairs of variables is one way of rooting out inconsistencies
- Removing responses with missing or incorrect values
- Correct missing or incorrect data if the correct value is known
- Going back to the data source and filling in the missing data variables
- Setting values to an average or other statistical value
This blog post from the American Evaluation Association provides an overview of Google Refine, a desktop application (downloadable) that can be used to calculate frequencies and multi-tabulate data from large datasets and clean up your data.
This paper from the University of Leipzig sets out to explain the main problems that data cleaning is able to correct and then provides an overview of the solutions that are available to implement the cleansing of data.
This paper from the Robert Wood Johnson Medical School outlines a step-by-step process for verifying that data values are correct or, at the very least, conform to a set of rules through the use of a data cleaning process.
Written by Associate Professor of Evaluation, Statistics, and Measurement at the University of Tennessee, Jenifer Morrow, the Brief Introduction to the 12 steps to data cleaning is a slide presentation that provides a concise overview to the importance
Rahm, E., & Hai Do, H. University of Leipzig, Germany, (n.d.). Data cleaning: Problems and current approaches . Retrieved from website: http://wwwiti.cs.uni-magdeburg.de/iti_db/lehre/dw/paper/data_cleaning.pdf
Wikipedia (2012). Data cleansing . Retrieved from http://en.wikipedia.org/wiki/Data_cleansing
Expand to view all resources related to 'Data cleaning'
- Data cleaning 101
'Data cleaning' is referenced in:
Framework/guide.
- Rainbow Framework : Manage data
Back to top
© 2022 BetterEvaluation. All right reserved.
- Policy Guidance
- Submitting Data
- Accessing Data
- About the Genomic Data Sharing (GDS) Policy
- Key Documents
- Preparing Genomic Data
- Extramural Grantees
- Non-NCI Funded Investigators
- Intramural Investigators
- Accessing Genomic Data
- Genomic Data Sharing Policy Contact Information
- ARPA-H BDF Toolbox
- Cancer Research Data Commons
- Childhood Cancer Data Initiative
- NCI-Department of Energy Collaboration
- Real-World Data
- U.S.-EU Artificial Intelligence Administrative Arrangement
- NCI Data Catalog
- CDISC Terminology
- FDA Terminology
- NCPDP Terminology
- Pediatric Terminology
- Metadata for Cancer Research
- Informatics Technology for Cancer Research (ITCR) Tools
- Generating and Collecting Data
- Cleaning Data
- Exploring and Analyzing Data
- Predictive Modeling
- Visualizing Data
- Sharing Data
- Cancer Data Science Course
- Training Guide Library
- Cancer Data Science Pulse Blog
- Data Science Seminar Series
- Jobs and Fellowships
- Contact CBIIT
- Organization
- CBIIT Director
- Staff Directory
- Application Support
- Genomic Data Sharing
- Cancer Vocabulary
- Learn About Cancer Data Science
- Improve My Data Science Skills
Cleaning Data: The Basics
What is data cleaning.
At its most basic level, data cleaning is the process of fixing or removing data that’s inaccurate, duplicated, or outside the scope of your research question.
Some errors might be hard to avoid. You may have made a mistake during data entry, or you might have a corrupt file. You may find the format is wrong for combining multiple data sets or different sources. Or you may have metadata that’s mislabeled.
Before beginning to clean your data, it’s a good idea to keep a copy of the raw data set. If you make an error during the cleaning stage, you can always go back to the original, and you won’t lose important information.
In working with data, remember the three “C”s:
- Complete —Avoid missing data. You can use default records as stand-ins for incomplete data sets. Or you can recode data using a different format or fill in missing values using a statistic tool. Be sure to use metadata that’s appropriate for the data type and topic.
- Consistent —Ensure that the data collected at the beginning of the study matches data from the end of the study (in both semantics and scope).
- Correct —Look for outliers and duplicates. Duplicate records can lead to incorrect calculations and impact statistical results so be sure to delete them. You can identify outliers using statistics (e.g., z scores or box plots). Before removing any outliers, consider the significance of these data and how removal could impact downstream analytics. Sometimes outliers are deceptive, but sometimes they offer insightful information.
Following these three Cs will help you when it comes time to aggregate data and will make filtering, selecting, and calculating more efficient.
Why Do We Need Clean Data for Cancer Research?
Accurate data supports sound decision making, helping you address your research question and allowing you to avoid misleading findings and costly mistakes.
What Do I Need to Know?
Quality data takes effort. Below are some typical areas that can cause problems:
- Mismatched or incomplete metadata . One of the most common problems occurs when researchers assign the wrong code. You may also find that codes change over time with the release of new versions. NCI Thesaurus can help you assign the correct codes. For more on the importance of semantics in data science , see the blogs, “ Semantics Primer ,” and “ Semantics Series: A Deep Dive Into Common Data Elements .”
- Inconsistent formatting. Review your formatting and carefully watch for data entry errors. Be sure that the entries exactly match your research, as many errors can occur during data entry. Check your columns to make certain you’ve used the same descriptors consistently. You can drop any columns that aren’t immediately relevant to your research question, and you can split columns as needed (depending on the software program that you’re using). Be sure to keep one entry per cell. You can flag any entries that need more attention (such as checking a patient’s medication history or confirming a date). You can always go back to those problem areas and resolve them when you have more information.
- Watch for bias. Data bias is another area that can result in misleading conclusions. Personal or societal biases can creep into research, even without your knowledge. It’s difficult to de-bias data during data cleaning. It’s better to think about the research questions you’ll ask and look for ways to offset bias before you collect the data. For example, you might want to recruit a range of study subjects by retooling your informed consent forms and broadening your outreach. You also might need to make adjustments to mitigate algorithm and data collection biases.
Repository Matters
You can maximize your data’s discoverability and re-use by uploading your files to a general or specialty data repository. Repositories serve as archives for data. They may have different data requirements. Some generalist collections allow you to upload a variety of formats and data types whereas specialty collections have very specific guidelines.
After you submit your data to a registry, the repository staff will do the following:
- Check your data for errors, inconsistencies, or missing information. Quality control includes regular checks for data completeness, accuracy, and adherence to coding standards.
- Validate your data. This may include registrars cross-checking data with multiple sources and/or verifying specific details with healthcare providers.
- Ensure your data are correctly linked. Data may be linked with other databases, such as vital records, to gather additional information and ensure comprehensive data capture for each case.
- Remove certain patient information. Personal identifiers, which link data to a specific person, are typically removed from the data to protect patient privacy. This is done before it is sent to a repository for broader distribution.
- Check that your data fits the repository’s system. Registries follow standardized coding systems and reporting guidelines to ensure consistency across different regions and over time, allowing for meaningful comparisons and analysis.
Setting up your data correctly from the start can help you avoid delays in formatting when it comes time to deposit your data, especially if your research is NIH funded. NIH’s Data Management and Sharing Policy requires making effective data management and sharing practices a routine part of scientific discovery.
Privacy is Vital
If you’re working with genetic data, imaging data, or other data that includes personal information, you must take steps to ensure patient privacy. The Health Insurance Portability and Accountability Act (HIPAA) requires you remove patients’ personal information.
The Informatics Technology for Cancer Research (ITCR) Program has a course, “ Ethical Data Handling for Cancer Research ,” that you can take to better understand important ethical principles of data management from a privacy, security, usability, and discoverability perspective.
Documentation is Key
Tracking how you cleaned your data can help save time in the future, reminding you of the types of errors you encountered and the approaches you used to fix those errors. It’s also good to document how you managed outliers.
If you use informatics tools in your research but have not had training in reproducibility tools and methods, take ITCR’s “ Intro to Reproducibility in Cancer Informatics ” course. You’ll gain skills in writing durable code, making a project open source with GitHub, analyzing documents, and more.
After you’ve completed the introductory course, take “ Advanced Reproducibility in Cancer Informatics ,” which will teach you more complex GitHub functions, how to engage in code review, how to modify a Docker image, and more.
Reminders to Keep in Mind
- Plan your data collection efforts well in advance of starting your study, and be sure to keep careful documentation. Doing this will minimize the time-consuming and tedious task of cleaning data.
- See the article, “ Generating and Collecting Data: The Basics ” for more tips.
- Technology also may be able to help lighten your data-cleaning workload. Traditionally, data cleaning has been an arduous task that relied heavily on human decisions. This may be changing, however, as technology helps make some of these decisions. For example, tools, both commercial and open source, are now available that can remove unnecessary columns, filter results, and validate data sets.
NCI Data Cleaning Resources and Initiatives
Now that you have a sense of the basics, use the following resources to discover more about the topic and understand NCI’s investment in this stage of the data science lifecycle.
- Semantics Series: A Deep Dive Into Common Data Elements : Learn how using proper descriptors can help you prepare your data for analysis.
- NCI’s Surveillance, Epidemiology, and End Results (SEER) Program has a training site with modules to help with collecting and recording cancer data. SEER also offers resources with links to reference materials and organizations that can help with coding and registering cancer cases.
- The NCI Cancer Research Data Commons offers a wide range of support to researchers —including tutorials, user guides, and office hours—to help them learn to use this cloud-based collection of data sets, accessible through its data commons or cloud resources, that also make thousands of analytical tools available.
Publications
- Interoperable Slide Microscopy Viewer and Annotation Tool for Imaging Data Science and Computational Pathology . Nature Communications , 2023. | Learn about Slim, an open-source, web-based slide microscopy viewer that helps facilitate interoperability with a range of existing medical imaging systems.
- Effects of Slide Storage on Detection of Molecular Markers by IHC and FISH in Endometrial Cancer Tissues From a Clinical Trial: An NRG Oncology/GOG Pilot Study . Applied Immunohistochemistry & Molecular Morphology , 2022. | See a study that showed that although it’s feasible to use aged-stored slides for identifying biomarkers for cancer, the results may modestly underestimate the true values in endometrial cancer.
- Uniform Genomic Data Analysis in the NCI Genomic Data Commons . Nature Communications , 2021. | Learn about the pipelines and workflows used to process and harmonize data in NCI’s Genomic Data Commons.
- Robustness Study of Noisy Annotation in Deep Learning Based Medical Image Segmentation . Physics in Medicine and Biology , 2020. | See a study showing that a deep network trained with noisy labels is inferior to that trained with reference annotation.
- Screen Technical Noise in Single Cell RNA Sequencing Data . Genomics , 2020. | Learn about a new data cleaning pipeline for single cell RNA-seq data.
- Building Portable and Reproducible Cancer Informatics Workflows: An RNA Sequencing Case Study . Methods in Molecular Biology , 2019. | See a case study using different tools in NCI’s Cancer Genomics Cloud for analyzing RNA sequencing data.
- QuagmiR: A Cloud-based Application for isomiR Big Data Analytics . Bioinformatics , 2019. | Learn about QuagmiR, a cloud-based tool for analyzing MicroRNA isoforms from next generation sequencing data.
- RNA-seq from Archival FFPE Breast Cancer Samples: Molecular Pathway Fidelity and Novel Discovery . BMC Medical Genomics , 2019. | See information on a formalin-fixed, paraffin-embedded, RNA sequencing pipeline for research on breast cancer.
- Scalable Open Science Approach for Mutation Calling of Tumor Exomes Using Multiple Genomic Pipelines . Cell Systems , 2018. | Learn about the “Multi-Center Mutation Calling in Multiple Cancers” project. See how this comprehensive encyclopedia of somatic mutations helps enable cross-tumor-type analyses using The Cancer Genome Atlas data sets.
- Ready to start your project? Get an overview of the data science lifecycle and what you should do in each stage .
- Want to learn the basic skills for cancer data science? Check out our basics skills video course .
- Need answers to data science questions? Visit our Training Guide Library .
Please participate
We are conducting a survey to assess the compute-intensive resource needs of the cancer research community. Regardless of your area of cancer research, your insights will contribute to a better understanding of computing needs and challenges for research that involves large amounts of data and analysis.
Root out friction in every digital experience, super-charge conversion rates, and optimise digital self-service
Uncover insights from any interaction, deliver AI-powered agent coaching, and reduce cost to serve
Increase revenue and loyalty with real-time insights and recommendations delivered straight to teams on the ground
Know how your people feel and empower managers to improve employee engagement, productivity, and retention
Take action in the moments that matter most along the employee journey and drive bottom line growth
Whatever they’re are saying, wherever they’re saying it, know exactly what’s going on with your people
Get faster, richer insights with qual and quant tools that make powerful market research available to everyone
Run concept tests, pricing studies, prototyping + more with fast, powerful studies designed by UX research experts
Track your brand performance 24/7 and act quickly to respond to opportunities and challenges in your market
Meet the operating system for experience management
- Free Account
- Product Demos
- For Digital
- For Customer Care
- For Human Resources
- For Researchers
- Financial Services
- All Industries
Popular Use Cases
- Customer Experience
- Employee Experience
- Employee Exit Interviews
- Net Promoter Score
- Voice of Customer
- Customer Success Hub
- Product Documentation
- Training & Certification
- XM Institute
- Popular Resources
- Customer Stories
- Artificial Intelligence
- Market Research
- Partnerships
- Marketplace
The annual gathering of the experience leaders at the world’s iconic brands building breakthrough business results.
- English/AU & NZ
- Español/Europa
- Español/América Latina
- Português Brasileiro
- REQUEST DEMO
- Experience Management
- Survey Analysis
- Survey Data Cleaning
Try Qualtrics for free
Survey data cleaning: how to get the most accurate survey data.
4 min read Before you analyse your survey results, data cleaning is a must-do. It helps you get the best quality data possible, so you can make more accurate decisions. Here’s how to get your data sparkling clean.
First things first – What is data cleaning?
Cleaning data means getting rid of any anomalous, incorrectly filled or otherwise “odd” results that could skew your analysis.
Some examples include:
- Straight-lining , where the respondent has selected the first response to every question, regardless of the question.
- Christmas-trees , where answers have been selected to create a visual pattern or picture – resembling a Christmas tree or some other deliberate design – rather than in response to the survey questions.
Not all problematic results are deliberate – you may also find duplicate responses caused by people accidentally filling in a survey twice or failing to realise that their submission had completed.
When you clean your survey data, you’re eliminating these ‘noisy’ responses that don’t add value and can confuse your end results. Think of it like weeding your garden to give your best plants more room to grow.
How to find the ‘dirt’ when data cleaning
There are a few methods experienced survey designers use spot the results that should be weeded out. These can involve looking at the metadata of the survey or visualising data to uncover patterns.
Find the fastest respondents
Time data can show where respondents have whizzed through a survey selecting answers without properly reading and considering the questions. Setting a ‘speed limit’ for your responses can help eliminate thoughtless or random answers.
Turn numeric data into graphics
For issues like Christmas tree or straight-lining respondents, it can be easier to spot problems if your data appears as a chart or graph rather than a table of numbers.
Review open-ended questions
Where your survey design requires participants to answer in their own words, you can spot problem data by noting where the open fields have been filled in with nonsense text. This could indicate that they survey has been completed by a bot rather than a human or where the survey respondent was not engaged with questions.
Learn more about open-ended questions
Edge cases to consider when cleaning data
Sometimes deciding whether to exclude certain survey responses from your final data set isn’t clear-cut. In these situations, you’ll need to make a choice depending on the volume of data you have and your overall goals for the survey.
These are answers that are numerically miles away from the rest of your data, or seem implausible from a common-sense point of view. This could be something like selecting a number above 16 for “how many hours a day do you spend watching TV”. It could be the result of a user error or a misunderstanding of the question. Or in some cases, it could be an unusual but accurate reply.
Self-contradictory answers
If a respondent’s answers seem inconsistent or don’t add up to a coherent picture, it could mean they’ve answered without reading carefully. For example, in one question they might tell you they’re vegetarian and in another tick ‘bacon’ as a favorite food.
Incomplete surveys
See how Qualtrics can help you get more accurate data
Related resources
Analysis & Reporting
Margin of Error 11 min read
Text analysis 44 min read, sentiment analysis 21 min read, behavioural analytics 12 min read, descriptive statistics 15 min read, statistical significance calculator 18 min read, zero-party data 12 min read, request demo.
Ready to learn more about Qualtrics?
Frequently asked questions
What is data cleaning.
Data cleaning involves spotting and resolving potential data inconsistencies or errors to improve your data quality. An error is any value (e.g., recorded weight) that doesn’t reflect the true value (e.g., actual weight) of something that’s being measured.
In this process, you review, analyze, detect, modify, or remove “dirty” data to make your dataset “clean.” Data cleaning is also called data cleansing or data scrubbing.
Frequently asked questions: Methodology
Attrition refers to participants leaving a study. It always happens to some extent—for example, in randomized controlled trials for medical research.
Differential attrition occurs when attrition or dropout rates differ systematically between the intervention and the control group . As a result, the characteristics of the participants who drop out differ from the characteristics of those who stay in the study. Because of this, study results may be biased .
Action research is conducted in order to solve a particular issue immediately, while case studies are often conducted over a longer period of time and focus more on observing and analyzing a particular ongoing phenomenon.
Action research is focused on solving a problem or informing individual and community-based knowledge in a way that impacts teaching, learning, and other related processes. It is less focused on contributing theoretical input, instead producing actionable input.
Action research is particularly popular with educators as a form of systematic inquiry because it prioritizes reflection and bridges the gap between theory and practice. Educators are able to simultaneously investigate an issue as they solve it, and the method is very iterative and flexible.
A cycle of inquiry is another name for action research . It is usually visualized in a spiral shape following a series of steps, such as “planning → acting → observing → reflecting.”
To make quantitative observations , you need to use instruments that are capable of measuring the quantity you want to observe. For example, you might use a ruler to measure the length of an object or a thermometer to measure its temperature.
Criterion validity and construct validity are both types of measurement validity . In other words, they both show you how accurately a method measures something.
While construct validity is the degree to which a test or other measurement method measures what it claims to measure, criterion validity is the degree to which a test can predictively (in the future) or concurrently (in the present) measure something.
Construct validity is often considered the overarching type of measurement validity . You need to have face validity , content validity , and criterion validity in order to achieve construct validity.
Convergent validity and discriminant validity are both subtypes of construct validity . Together, they help you evaluate whether a test measures the concept it was designed to measure.
- Convergent validity indicates whether a test that is designed to measure a particular construct correlates with other tests that assess the same or similar construct.
- Discriminant validity indicates whether two tests that should not be highly related to each other are indeed not related. This type of validity is also called divergent validity .
You need to assess both in order to demonstrate construct validity. Neither one alone is sufficient for establishing construct validity.
- Discriminant validity indicates whether two tests that should not be highly related to each other are indeed not related
Content validity shows you how accurately a test or other measurement method taps into the various aspects of the specific construct you are researching.
In other words, it helps you answer the question: “does the test measure all aspects of the construct I want to measure?” If it does, then the test has high content validity.
The higher the content validity, the more accurate the measurement of the construct.
If the test fails to include parts of the construct, or irrelevant parts are included, the validity of the instrument is threatened, which brings your results into question.
Face validity and content validity are similar in that they both evaluate how suitable the content of a test is. The difference is that face validity is subjective, and assesses content at surface level.
When a test has strong face validity, anyone would agree that the test’s questions appear to measure what they are intended to measure.
For example, looking at a 4th grade math test consisting of problems in which students have to add and multiply, most people would agree that it has strong face validity (i.e., it looks like a math test).
On the other hand, content validity evaluates how well a test represents all the aspects of a topic. Assessing content validity is more systematic and relies on expert evaluation. of each question, analyzing whether each one covers the aspects that the test was designed to cover.
A 4th grade math test would have high content validity if it covered all the skills taught in that grade. Experts(in this case, math teachers), would have to evaluate the content validity by comparing the test to the learning objectives.
Snowball sampling is a non-probability sampling method . Unlike probability sampling (which involves some form of random selection ), the initial individuals selected to be studied are the ones who recruit new participants.
Because not every member of the target population has an equal chance of being recruited into the sample, selection in snowball sampling is non-random.
Snowball sampling is a non-probability sampling method , where there is not an equal chance for every member of the population to be included in the sample .
This means that you cannot use inferential statistics and make generalizations —often the goal of quantitative research . As such, a snowball sample is not representative of the target population and is usually a better fit for qualitative research .
Snowball sampling relies on the use of referrals. Here, the researcher recruits one or more initial participants, who then recruit the next ones.
Participants share similar characteristics and/or know each other. Because of this, not every member of the population has an equal chance of being included in the sample, giving rise to sampling bias .
Snowball sampling is best used in the following cases:
- If there is no sampling frame available (e.g., people with a rare disease)
- If the population of interest is hard to access or locate (e.g., people experiencing homelessness)
- If the research focuses on a sensitive topic (e.g., extramarital affairs)
The reproducibility and replicability of a study can be ensured by writing a transparent, detailed method section and using clear, unambiguous language.
Reproducibility and replicability are related terms.
- Reproducing research entails reanalyzing the existing data in the same manner.
- Replicating (or repeating ) the research entails reconducting the entire analysis, including the collection of new data .
- A successful reproduction shows that the data analyses were conducted in a fair and honest manner.
- A successful replication shows that the reliability of the results is high.
Stratified sampling and quota sampling both involve dividing the population into subgroups and selecting units from each subgroup. The purpose in both cases is to select a representative sample and/or to allow comparisons between subgroups.
The main difference is that in stratified sampling, you draw a random sample from each subgroup ( probability sampling ). In quota sampling you select a predetermined number or proportion of units, in a non-random manner ( non-probability sampling ).
Purposive and convenience sampling are both sampling methods that are typically used in qualitative data collection.
A convenience sample is drawn from a source that is conveniently accessible to the researcher. Convenience sampling does not distinguish characteristics among the participants. On the other hand, purposive sampling focuses on selecting participants possessing characteristics associated with the research study.
The findings of studies based on either convenience or purposive sampling can only be generalized to the (sub)population from which the sample is drawn, and not to the entire population.
Random sampling or probability sampling is based on random selection. This means that each unit has an equal chance (i.e., equal probability) of being included in the sample.
On the other hand, convenience sampling involves stopping people at random, which means that not everyone has an equal chance of being selected depending on the place, time, or day you are collecting your data.
Convenience sampling and quota sampling are both non-probability sampling methods. They both use non-random criteria like availability, geographical proximity, or expert knowledge to recruit study participants.
However, in convenience sampling, you continue to sample units or cases until you reach the required sample size.
In quota sampling, you first need to divide your population of interest into subgroups (strata) and estimate their proportions (quota) in the population. Then you can start your data collection, using convenience sampling to recruit participants, until the proportions in each subgroup coincide with the estimated proportions in the population.
A sampling frame is a list of every member in the entire population . It is important that the sampling frame is as complete as possible, so that your sample accurately reflects your population.
Stratified and cluster sampling may look similar, but bear in mind that groups created in cluster sampling are heterogeneous , so the individual characteristics in the cluster vary. In contrast, groups created in stratified sampling are homogeneous , as units share characteristics.
Relatedly, in cluster sampling you randomly select entire groups and include all units of each group in your sample. However, in stratified sampling, you select some units of all groups and include them in your sample. In this way, both methods can ensure that your sample is representative of the target population .
A systematic review is secondary research because it uses existing research. You don’t collect new data yourself.
The key difference between observational studies and experimental designs is that a well-done observational study does not influence the responses of participants, while experiments do have some sort of treatment condition applied to at least some participants by random assignment .
An observational study is a great choice for you if your research question is based purely on observations. If there are ethical, logistical, or practical concerns that prevent you from conducting a traditional experiment , an observational study may be a good choice. In an observational study, there is no interference or manipulation of the research subjects, as well as no control or treatment groups .
It’s often best to ask a variety of people to review your measurements. You can ask experts, such as other researchers, or laypeople, such as potential participants, to judge the face validity of tests.
While experts have a deep understanding of research methods , the people you’re studying can provide you with valuable insights you may have missed otherwise.
Face validity is important because it’s a simple first step to measuring the overall validity of a test or technique. It’s a relatively intuitive, quick, and easy way to start checking whether a new measure seems useful at first glance.
Good face validity means that anyone who reviews your measure says that it seems to be measuring what it’s supposed to. With poor face validity, someone reviewing your measure may be left confused about what you’re measuring and why you’re using this method.
Face validity is about whether a test appears to measure what it’s supposed to measure. This type of validity is concerned with whether a measure seems relevant and appropriate for what it’s assessing only on the surface.
Statistical analyses are often applied to test validity with data from your measures. You test convergent validity and discriminant validity with correlations to see if results from your test are positively or negatively related to those of other established tests.
You can also use regression analyses to assess whether your measure is actually predictive of outcomes that you expect it to predict theoretically. A regression analysis that supports your expectations strengthens your claim of construct validity .
When designing or evaluating a measure, construct validity helps you ensure you’re actually measuring the construct you’re interested in. If you don’t have construct validity, you may inadvertently measure unrelated or distinct constructs and lose precision in your research.
Construct validity is often considered the overarching type of measurement validity , because it covers all of the other types. You need to have face validity , content validity , and criterion validity to achieve construct validity.
Construct validity is about how well a test measures the concept it was designed to evaluate. It’s one of four types of measurement validity , which includes construct validity, face validity , and criterion validity.
There are two subtypes of construct validity.
- Convergent validity : The extent to which your measure corresponds to measures of related constructs
- Discriminant validity : The extent to which your measure is unrelated or negatively related to measures of distinct constructs
Naturalistic observation is a valuable tool because of its flexibility, external validity , and suitability for topics that can’t be studied in a lab setting.
The downsides of naturalistic observation include its lack of scientific control , ethical considerations , and potential for bias from observers and subjects.
Naturalistic observation is a qualitative research method where you record the behaviors of your research subjects in real world settings. You avoid interfering or influencing anything in a naturalistic observation.
You can think of naturalistic observation as “people watching” with a purpose.
A dependent variable is what changes as a result of the independent variable manipulation in experiments . It’s what you’re interested in measuring, and it “depends” on your independent variable.
In statistics, dependent variables are also called:
- Response variables (they respond to a change in another variable)
- Outcome variables (they represent the outcome you want to measure)
- Left-hand-side variables (they appear on the left-hand side of a regression equation)
An independent variable is the variable you manipulate, control, or vary in an experimental study to explore its effects. It’s called “independent” because it’s not influenced by any other variables in the study.
Independent variables are also called:
- Explanatory variables (they explain an event or outcome)
- Predictor variables (they can be used to predict the value of a dependent variable)
- Right-hand-side variables (they appear on the right-hand side of a regression equation).
As a rule of thumb, questions related to thoughts, beliefs, and feelings work well in focus groups. Take your time formulating strong questions, paying special attention to phrasing. Be careful to avoid leading questions , which can bias your responses.
Overall, your focus group questions should be:
- Open-ended and flexible
- Impossible to answer with “yes” or “no” (questions that start with “why” or “how” are often best)
- Unambiguous, getting straight to the point while still stimulating discussion
- Unbiased and neutral
A structured interview is a data collection method that relies on asking questions in a set order to collect data on a topic. They are often quantitative in nature. Structured interviews are best used when:
- You already have a very clear understanding of your topic. Perhaps significant research has already been conducted, or you have done some prior research yourself, but you already possess a baseline for designing strong structured questions.
- You are constrained in terms of time or resources and need to analyze your data quickly and efficiently.
- Your research question depends on strong parity between participants, with environmental conditions held constant.
More flexible interview options include semi-structured interviews , unstructured interviews , and focus groups .
Social desirability bias is the tendency for interview participants to give responses that will be viewed favorably by the interviewer or other participants. It occurs in all types of interviews and surveys , but is most common in semi-structured interviews , unstructured interviews , and focus groups .
Social desirability bias can be mitigated by ensuring participants feel at ease and comfortable sharing their views. Make sure to pay attention to your own body language and any physical or verbal cues, such as nodding or widening your eyes.
This type of bias can also occur in observations if the participants know they’re being observed. They might alter their behavior accordingly.
The interviewer effect is a type of bias that emerges when a characteristic of an interviewer (race, age, gender identity, etc.) influences the responses given by the interviewee.
There is a risk of an interviewer effect in all types of interviews , but it can be mitigated by writing really high-quality interview questions.
A semi-structured interview is a blend of structured and unstructured types of interviews. Semi-structured interviews are best used when:
- You have prior interview experience. Spontaneous questions are deceptively challenging, and it’s easy to accidentally ask a leading question or make a participant uncomfortable.
- Your research question is exploratory in nature. Participant answers can guide future research questions and help you develop a more robust knowledge base for future research.
An unstructured interview is the most flexible type of interview, but it is not always the best fit for your research topic.
Unstructured interviews are best used when:
- You are an experienced interviewer and have a very strong background in your research topic, since it is challenging to ask spontaneous, colloquial questions.
- Your research question is exploratory in nature. While you may have developed hypotheses, you are open to discovering new or shifting viewpoints through the interview process.
- You are seeking descriptive data, and are ready to ask questions that will deepen and contextualize your initial thoughts and hypotheses.
- Your research depends on forming connections with your participants and making them feel comfortable revealing deeper emotions, lived experiences, or thoughts.
The four most common types of interviews are:
- Structured interviews : The questions are predetermined in both topic and order.
- Semi-structured interviews : A few questions are predetermined, but other questions aren’t planned.
- Unstructured interviews : None of the questions are predetermined.
- Focus group interviews : The questions are presented to a group instead of one individual.
Deductive reasoning is commonly used in scientific research, and it’s especially associated with quantitative research .
In research, you might have come across something called the hypothetico-deductive method . It’s the scientific method of testing hypotheses to check whether your predictions are substantiated by real-world data.
Deductive reasoning is a logical approach where you progress from general ideas to specific conclusions. It’s often contrasted with inductive reasoning , where you start with specific observations and form general conclusions.
Deductive reasoning is also called deductive logic.
There are many different types of inductive reasoning that people use formally or informally.
Here are a few common types:
- Inductive generalization : You use observations about a sample to come to a conclusion about the population it came from.
- Statistical generalization: You use specific numbers about samples to make statements about populations.
- Causal reasoning: You make cause-and-effect links between different things.
- Sign reasoning: You make a conclusion about a correlational relationship between different things.
- Analogical reasoning: You make a conclusion about something based on its similarities to something else.
Inductive reasoning is a bottom-up approach, while deductive reasoning is top-down.
Inductive reasoning takes you from the specific to the general, while in deductive reasoning, you make inferences by going from general premises to specific conclusions.
In inductive research , you start by making observations or gathering data. Then, you take a broad scan of your data and search for patterns. Finally, you make general conclusions that you might incorporate into theories.
Inductive reasoning is a method of drawing conclusions by going from the specific to the general. It’s usually contrasted with deductive reasoning, where you proceed from general information to specific conclusions.
Inductive reasoning is also called inductive logic or bottom-up reasoning.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Triangulation can help:
- Reduce research bias that comes from using a single method, theory, or investigator
- Enhance validity by approaching the same topic with different tools
- Establish credibility by giving you a complete picture of the research problem
But triangulation can also pose problems:
- It’s time-consuming and labor-intensive, often involving an interdisciplinary team.
- Your results may be inconsistent or even contradictory.
There are four main types of triangulation :
- Data triangulation : Using data from different times, spaces, and people
- Investigator triangulation : Involving multiple researchers in collecting or analyzing data
- Theory triangulation : Using varying theoretical perspectives in your research
- Methodological triangulation : Using different methodologies to approach the same topic
Many academic fields use peer review , largely to determine whether a manuscript is suitable for publication. Peer review enhances the credibility of the published manuscript.
However, peer review is also common in non-academic settings. The United Nations, the European Union, and many individual nations use peer review to evaluate grant applications. It is also widely used in medical and health-related fields as a teaching or quality-of-care measure.
Peer assessment is often used in the classroom as a pedagogical tool. Both receiving feedback and providing it are thought to enhance the learning process, helping students think critically and collaboratively.
Peer review can stop obviously problematic, falsified, or otherwise untrustworthy research from being published. It also represents an excellent opportunity to get feedback from renowned experts in your field. It acts as a first defense, helping you ensure your argument is clear and that there are no gaps, vague terms, or unanswered questions for readers who weren’t involved in the research process.
Peer-reviewed articles are considered a highly credible source due to this stringent process they go through before publication.
In general, the peer review process follows the following steps:
- First, the author submits the manuscript to the editor.
- Reject the manuscript and send it back to author, or
- Send it onward to the selected peer reviewer(s)
- Next, the peer review process occurs. The reviewer provides feedback, addressing any major or minor issues with the manuscript, and gives their advice regarding what edits should be made.
- Lastly, the edited manuscript is sent back to the author. They input the edits, and resubmit it to the editor for publication.
Exploratory research is often used when the issue you’re studying is new or when the data collection process is challenging for some reason.
You can use exploratory research if you have a general idea or a specific question that you want to study but there is no preexisting knowledge or paradigm with which to study it.
Exploratory research is a methodology approach that explores research questions that have not previously been studied in depth. It is often used when the issue you’re studying is new, or the data collection process is challenging in some way.
Explanatory research is used to investigate how or why a phenomenon occurs. Therefore, this type of research is often one of the first stages in the research process , serving as a jumping-off point for future research.
Exploratory research aims to explore the main aspects of an under-researched problem, while explanatory research aims to explain the causes and consequences of a well-defined problem.
Explanatory research is a research method used to investigate how or why something occurs when only a small amount of information is available pertaining to that topic. It can help you increase your understanding of a given topic.
Clean data are valid, accurate, complete, consistent, unique, and uniform. Dirty data include inconsistencies and errors.
Dirty data can come from any part of the research process, including poor research design , inappropriate measurement materials, or flawed data entry.
Data cleaning takes place between data collection and data analyses. But you can use some methods even before collecting data.
For clean data, you should start by designing measures that collect valid data. Data validation at the time of data entry or collection helps you minimize the amount of data cleaning you’ll need to do.
After data collection, you can use data standardization and data transformation to clean your data. You’ll also deal with any missing values, outliers, and duplicate values.
Every dataset requires different techniques to clean dirty data , but you need to address these issues in a systematic way. You focus on finding and resolving data points that don’t agree or fit with the rest of your dataset.
These data might be missing values, outliers, duplicate values, incorrectly formatted, or irrelevant. You’ll start with screening and diagnosing your data. Then, you’ll often standardize and accept or remove data to make your dataset consistent and valid.
Data cleaning is necessary for valid and appropriate analyses. Dirty data contain inconsistencies or errors , but cleaning your data helps you minimize or resolve these.
Without data cleaning, you could end up with a Type I or II error in your conclusion. These types of erroneous conclusions can be practically significant with important consequences, because they lead to misplaced investments or missed opportunities.
Research misconduct means making up or falsifying data, manipulating data analyses, or misrepresenting results in research reports. It’s a form of academic fraud.
These actions are committed intentionally and can have serious consequences; research misconduct is not a simple mistake or a point of disagreement but a serious ethical failure.
Anonymity means you don’t know who the participants are, while confidentiality means you know who they are but remove identifying information from your research report. Both are important ethical considerations .
You can only guarantee anonymity by not collecting any personally identifying information—for example, names, phone numbers, email addresses, IP addresses, physical characteristics, photos, or videos.
You can keep data confidential by using aggregate information in your research report, so that you only refer to groups of participants rather than individuals.
Research ethics matter for scientific integrity, human rights and dignity, and collaboration between science and society. These principles make sure that participation in studies is voluntary, informed, and safe.
Ethical considerations in research are a set of principles that guide your research designs and practices. These principles include voluntary participation, informed consent, anonymity, confidentiality, potential for harm, and results communication.
Scientists and researchers must always adhere to a certain code of conduct when collecting data from others .
These considerations protect the rights of research participants, enhance research validity , and maintain scientific integrity.
In multistage sampling , you can use probability or non-probability sampling methods .
For a probability sample, you have to conduct probability sampling at every stage.
You can mix it up by using simple random sampling , systematic sampling , or stratified sampling to select units at different stages, depending on what is applicable and relevant to your study.
Multistage sampling can simplify data collection when you have large, geographically spread samples, and you can obtain a probability sample without a complete sampling frame.
But multistage sampling may not lead to a representative sample, and larger samples are needed for multistage samples to achieve the statistical properties of simple random samples .
These are four of the most common mixed methods designs :
- Convergent parallel: Quantitative and qualitative data are collected at the same time and analyzed separately. After both analyses are complete, compare your results to draw overall conclusions.
- Embedded: Quantitative and qualitative data are collected at the same time, but within a larger quantitative or qualitative design. One type of data is secondary to the other.
- Explanatory sequential: Quantitative data is collected and analyzed first, followed by qualitative data. You can use this design if you think your qualitative data will explain and contextualize your quantitative findings.
- Exploratory sequential: Qualitative data is collected and analyzed first, followed by quantitative data. You can use this design if you think the quantitative data will confirm or validate your qualitative findings.
Triangulation in research means using multiple datasets, methods, theories and/or investigators to address a research question. It’s a research strategy that can help you enhance the validity and credibility of your findings.
Triangulation is mainly used in qualitative research , but it’s also commonly applied in quantitative research . Mixed methods research always uses triangulation.
In multistage sampling , or multistage cluster sampling, you draw a sample from a population using smaller and smaller groups at each stage.
This method is often used to collect data from a large, geographically spread group of people in national surveys, for example. You take advantage of hierarchical groupings (e.g., from state to city to neighborhood) to create a sample that’s less expensive and time-consuming to collect data from.
No, the steepness or slope of the line isn’t related to the correlation coefficient value. The correlation coefficient only tells you how closely your data fit on a line, so two datasets with the same correlation coefficient can have very different slopes.
To find the slope of the line, you’ll need to perform a regression analysis .
Correlation coefficients always range between -1 and 1.
The sign of the coefficient tells you the direction of the relationship: a positive value means the variables change together in the same direction, while a negative value means they change together in opposite directions.
The absolute value of a number is equal to the number without its sign. The absolute value of a correlation coefficient tells you the magnitude of the correlation: the greater the absolute value, the stronger the correlation.
These are the assumptions your data must meet if you want to use Pearson’s r :
- Both variables are on an interval or ratio level of measurement
- Data from both variables follow normal distributions
- Your data have no outliers
- Your data is from a random or representative sample
- You expect a linear relationship between the two variables
Quantitative research designs can be divided into two main categories:
- Correlational and descriptive designs are used to investigate characteristics, averages, trends, and associations between variables.
- Experimental and quasi-experimental designs are used to test causal relationships .
Qualitative research designs tend to be more flexible. Common types of qualitative design include case study , ethnography , and grounded theory designs.
A well-planned research design helps ensure that your methods match your research aims, that you collect high-quality data, and that you use the right kind of analysis to answer your questions, utilizing credible sources . This allows you to draw valid , trustworthy conclusions.
The priorities of a research design can vary depending on the field, but you usually have to specify:
- Your research questions and/or hypotheses
- Your overall approach (e.g., qualitative or quantitative )
- The type of design you’re using (e.g., a survey , experiment , or case study )
- Your sampling methods or criteria for selecting subjects
- Your data collection methods (e.g., questionnaires , observations)
- Your data collection procedures (e.g., operationalization , timing and data management)
- Your data analysis methods (e.g., statistical tests or thematic analysis )
A research design is a strategy for answering your research question . It defines your overall approach and determines how you will collect and analyze data.
Questionnaires can be self-administered or researcher-administered.
Self-administered questionnaires can be delivered online or in paper-and-pen formats, in person or through mail. All questions are standardized so that all respondents receive the same questions with identical wording.
Researcher-administered questionnaires are interviews that take place by phone, in-person, or online between researchers and respondents. You can gain deeper insights by clarifying questions for respondents or asking follow-up questions.
You can organize the questions logically, with a clear progression from simple to complex, or randomly between respondents. A logical flow helps respondents process the questionnaire easier and quicker, but it may lead to bias. Randomization can minimize the bias from order effects.
Closed-ended, or restricted-choice, questions offer respondents a fixed set of choices to select from. These questions are easier to answer quickly.
Open-ended or long-form questions allow respondents to answer in their own words. Because there are no restrictions on their choices, respondents can answer in ways that researchers may not have otherwise considered.
A questionnaire is a data collection tool or instrument, while a survey is an overarching research method that involves collecting and analyzing data from people using questionnaires.
The third variable and directionality problems are two main reasons why correlation isn’t causation .
The third variable problem means that a confounding variable affects both variables to make them seem causally related when they are not.
The directionality problem is when two variables correlate and might actually have a causal relationship, but it’s impossible to conclude which variable causes changes in the other.
Correlation describes an association between variables : when one variable changes, so does the other. A correlation is a statistical indicator of the relationship between variables.
Causation means that changes in one variable brings about changes in the other (i.e., there is a cause-and-effect relationship between variables). The two variables are correlated with each other, and there’s also a causal link between them.
While causation and correlation can exist simultaneously, correlation does not imply causation. In other words, correlation is simply a relationship where A relates to B—but A doesn’t necessarily cause B to happen (or vice versa). Mistaking correlation for causation is a common error and can lead to false cause fallacy .
Controlled experiments establish causality, whereas correlational studies only show associations between variables.
- In an experimental design , you manipulate an independent variable and measure its effect on a dependent variable. Other variables are controlled so they can’t impact the results.
- In a correlational design , you measure variables without manipulating any of them. You can test whether your variables change together, but you can’t be sure that one variable caused a change in another.
In general, correlational research is high in external validity while experimental research is high in internal validity .
A correlation is usually tested for two variables at a time, but you can test correlations between three or more variables.
A correlation coefficient is a single number that describes the strength and direction of the relationship between your variables.
Different types of correlation coefficients might be appropriate for your data based on their levels of measurement and distributions . The Pearson product-moment correlation coefficient (Pearson’s r ) is commonly used to assess a linear relationship between two quantitative variables.
A correlational research design investigates relationships between two variables (or more) without the researcher controlling or manipulating any of them. It’s a non-experimental type of quantitative research .
A correlation reflects the strength and/or direction of the association between two or more variables.
- A positive correlation means that both variables change in the same direction.
- A negative correlation means that the variables change in opposite directions.
- A zero correlation means there’s no relationship between the variables.
Random error is almost always present in scientific studies, even in highly controlled settings. While you can’t eradicate it completely, you can reduce random error by taking repeated measurements, using a large sample, and controlling extraneous variables .
You can avoid systematic error through careful design of your sampling , data collection , and analysis procedures. For example, use triangulation to measure your variables using multiple methods; regularly calibrate instruments or procedures; use random sampling and random assignment ; and apply masking (blinding) where possible.
Systematic error is generally a bigger problem in research.
With random error, multiple measurements will tend to cluster around the true value. When you’re collecting data from a large sample , the errors in different directions will cancel each other out.
Systematic errors are much more problematic because they can skew your data away from the true value. This can lead you to false conclusions ( Type I and II errors ) about the relationship between the variables you’re studying.
Random and systematic error are two types of measurement error.
Random error is a chance difference between the observed and true values of something (e.g., a researcher misreading a weighing scale records an incorrect measurement).
Systematic error is a consistent or proportional difference between the observed and true values of something (e.g., a miscalibrated scale consistently records weights as higher than they actually are).
On graphs, the explanatory variable is conventionally placed on the x-axis, while the response variable is placed on the y-axis.
- If you have quantitative variables , use a scatterplot or a line graph.
- If your response variable is categorical, use a scatterplot or a line graph.
- If your explanatory variable is categorical, use a bar graph.
The term “ explanatory variable ” is sometimes preferred over “ independent variable ” because, in real world contexts, independent variables are often influenced by other variables. This means they aren’t totally independent.
Multiple independent variables may also be correlated with each other, so “explanatory variables” is a more appropriate term.
The difference between explanatory and response variables is simple:
- An explanatory variable is the expected cause, and it explains the results.
- A response variable is the expected effect, and it responds to other variables.
In a controlled experiment , all extraneous variables are held constant so that they can’t influence the results. Controlled experiments require:
- A control group that receives a standard treatment, a fake treatment, or no treatment.
- Random assignment of participants to ensure the groups are equivalent.
Depending on your study topic, there are various other methods of controlling variables .
There are 4 main types of extraneous variables :
- Demand characteristics : environmental cues that encourage participants to conform to researchers’ expectations.
- Experimenter effects : unintentional actions by researchers that influence study outcomes.
- Situational variables : environmental variables that alter participants’ behaviors.
- Participant variables : any characteristic or aspect of a participant’s background that could affect study results.
An extraneous variable is any variable that you’re not investigating that can potentially affect the dependent variable of your research study.
A confounding variable is a type of extraneous variable that not only affects the dependent variable, but is also related to the independent variable.
In a factorial design, multiple independent variables are tested.
If you test two variables, each level of one independent variable is combined with each level of the other independent variable to create different conditions.
Within-subjects designs have many potential threats to internal validity , but they are also very statistically powerful .
Advantages:
- Only requires small samples
- Statistically powerful
- Removes the effects of individual differences on the outcomes
Disadvantages:
- Internal validity threats reduce the likelihood of establishing a direct relationship between variables
- Time-related effects, such as growth, can influence the outcomes
- Carryover effects mean that the specific order of different treatments affect the outcomes
While a between-subjects design has fewer threats to internal validity , it also requires more participants for high statistical power than a within-subjects design .
- Prevents carryover effects of learning and fatigue.
- Shorter study duration.
- Needs larger samples for high power.
- Uses more resources to recruit participants, administer sessions, cover costs, etc.
- Individual differences may be an alternative explanation for results.
Yes. Between-subjects and within-subjects designs can be combined in a single study when you have two or more independent variables (a factorial design). In a mixed factorial design, one variable is altered between subjects and another is altered within subjects.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word “between” means that you’re comparing different conditions between groups, while the word “within” means you’re comparing different conditions within the same group.
Random assignment is used in experiments with a between-groups or independent measures design. In this research design, there’s usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable.
In general, you should always use random assignment in this type of experimental design when it is ethically possible and makes sense for your study topic.
To implement random assignment , assign a unique number to every member of your study’s sample .
Then, you can use a random number generator or a lottery method to randomly assign each number to a control or experimental group. You can also do so manually, by flipping a coin or rolling a dice to randomly assign participants to groups.
Random selection, or random sampling , is a way of selecting members of a population for your study’s sample.
In contrast, random assignment is a way of sorting the sample into control and experimental groups.
Random sampling enhances the external validity or generalizability of your results, while random assignment improves the internal validity of your study.
In experimental research, random assignment is a way of placing participants from your sample into different groups using randomization. With this method, every member of the sample has a known or equal chance of being placed in a control group or an experimental group.
“Controlling for a variable” means measuring extraneous variables and accounting for them statistically to remove their effects on other variables.
Researchers often model control variable data along with independent and dependent variable data in regression analyses and ANCOVAs . That way, you can isolate the control variable’s effects from the relationship between the variables of interest.
Control variables help you establish a correlational or causal relationship between variables by enhancing internal validity .
If you don’t control relevant extraneous variables , they may influence the outcomes of your study, and you may not be able to demonstrate that your results are really an effect of your independent variable .
A control variable is any variable that’s held constant in a research study. It’s not a variable of interest in the study, but it’s controlled because it could influence the outcomes.
Including mediators and moderators in your research helps you go beyond studying a simple relationship between two variables for a fuller picture of the real world. They are important to consider when studying complex correlational or causal relationships.
Mediators are part of the causal pathway of an effect, and they tell you how or why an effect takes place. Moderators usually help you judge the external validity of your study by identifying the limitations of when the relationship between variables holds.
If something is a mediating variable :
- It’s caused by the independent variable .
- It influences the dependent variable
- When it’s taken into account, the statistical correlation between the independent and dependent variables is higher than when it isn’t considered.
A confounder is a third variable that affects variables of interest and makes them seem related when they are not. In contrast, a mediator is the mechanism of a relationship between two variables: it explains the process by which they are related.
A mediator variable explains the process through which two variables are related, while a moderator variable affects the strength and direction of that relationship.
There are three key steps in systematic sampling :
- Define and list your population , ensuring that it is not ordered in a cyclical or periodic order.
- Decide on your sample size and calculate your interval, k , by dividing your population by your target sample size.
- Choose every k th member of the population as your sample.
Systematic sampling is a probability sampling method where researchers select members of the population at a regular interval – for example, by selecting every 15th person on a list of the population. If the population is in a random order, this can imitate the benefits of simple random sampling .
Yes, you can create a stratified sample using multiple characteristics, but you must ensure that every participant in your study belongs to one and only one subgroup. In this case, you multiply the numbers of subgroups for each characteristic to get the total number of groups.
For example, if you were stratifying by location with three subgroups (urban, rural, or suburban) and marital status with five subgroups (single, divorced, widowed, married, or partnered), you would have 3 x 5 = 15 subgroups.
You should use stratified sampling when your sample can be divided into mutually exclusive and exhaustive subgroups that you believe will take on different mean values for the variable that you’re studying.
Using stratified sampling will allow you to obtain more precise (with lower variance ) statistical estimates of whatever you are trying to measure.
For example, say you want to investigate how income differs based on educational attainment, but you know that this relationship can vary based on race. Using stratified sampling, you can ensure you obtain a large enough sample from each racial group, allowing you to draw more precise conclusions.
In stratified sampling , researchers divide subjects into subgroups called strata based on characteristics that they share (e.g., race, gender, educational attainment).
Once divided, each subgroup is randomly sampled using another probability sampling method.
Cluster sampling is more time- and cost-efficient than other probability sampling methods , particularly when it comes to large samples spread across a wide geographical area.
However, it provides less statistical certainty than other methods, such as simple random sampling , because it is difficult to ensure that your clusters properly represent the population as a whole.
There are three types of cluster sampling : single-stage, double-stage and multi-stage clustering. In all three types, you first divide the population into clusters, then randomly select clusters for use in your sample.
- In single-stage sampling , you collect data from every unit within the selected clusters.
- In double-stage sampling , you select a random sample of units from within the clusters.
- In multi-stage sampling , you repeat the procedure of randomly sampling elements from within the clusters until you have reached a manageable sample.
Cluster sampling is a probability sampling method in which you divide a population into clusters, such as districts or schools, and then randomly select some of these clusters as your sample.
The clusters should ideally each be mini-representations of the population as a whole.
If properly implemented, simple random sampling is usually the best sampling method for ensuring both internal and external validity . However, it can sometimes be impractical and expensive to implement, depending on the size of the population to be studied,
If you have a list of every member of the population and the ability to reach whichever members are selected, you can use simple random sampling.
The American Community Survey is an example of simple random sampling . In order to collect detailed data on the population of the US, the Census Bureau officials randomly select 3.5 million households per year and use a variety of methods to convince them to fill out the survey.
Simple random sampling is a type of probability sampling in which the researcher randomly selects a subset of participants from a population . Each member of the population has an equal chance of being selected. Data is then collected from as large a percentage as possible of this random subset.
Quasi-experimental design is most useful in situations where it would be unethical or impractical to run a true experiment .
Quasi-experiments have lower internal validity than true experiments, but they often have higher external validity as they can use real-world interventions instead of artificial laboratory settings.
A quasi-experiment is a type of research design that attempts to establish a cause-and-effect relationship. The main difference with a true experiment is that the groups are not randomly assigned.
Blinding is important to reduce research bias (e.g., observer bias , demand characteristics ) and ensure a study’s internal validity .
If participants know whether they are in a control or treatment group , they may adjust their behavior in ways that affect the outcome that researchers are trying to measure. If the people administering the treatment are aware of group assignment, they may treat participants differently and thus directly or indirectly influence the final results.
- In a single-blind study , only the participants are blinded.
- In a double-blind study , both participants and experimenters are blinded.
- In a triple-blind study , the assignment is hidden not only from participants and experimenters, but also from the researchers analyzing the data.
Blinding means hiding who is assigned to the treatment group and who is assigned to the control group in an experiment .
A true experiment (a.k.a. a controlled experiment) always includes at least one control group that doesn’t receive the experimental treatment.
However, some experiments use a within-subjects design to test treatments without a control group. In these designs, you usually compare one group’s outcomes before and after a treatment (instead of comparing outcomes between different groups).
For strong internal validity , it’s usually best to include a control group if possible. Without a control group, it’s harder to be certain that the outcome was caused by the experimental treatment and not by other variables.
An experimental group, also known as a treatment group, receives the treatment whose effect researchers wish to study, whereas a control group does not. They should be identical in all other ways.
Individual Likert-type questions are generally considered ordinal data , because the items have clear rank order, but don’t have an even distribution.
Overall Likert scale scores are sometimes treated as interval data. These scores are considered to have directionality and even spacing between them.
The type of data determines what statistical tests you should use to analyze your data.
A Likert scale is a rating scale that quantitatively assesses opinions, attitudes, or behaviors. It is made up of 4 or more questions that measure a single attitude or trait when response scores are combined.
To use a Likert scale in a survey , you present participants with Likert-type questions or statements, and a continuum of items, usually with 5 or 7 possible responses, to capture their degree of agreement.
In scientific research, concepts are the abstract ideas or phenomena that are being studied (e.g., educational achievement). Variables are properties or characteristics of the concept (e.g., performance at school), while indicators are ways of measuring or quantifying variables (e.g., yearly grade reports).
The process of turning abstract concepts into measurable variables and indicators is called operationalization .
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organize your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
There are five common approaches to qualitative research :
- Grounded theory involves collecting data in order to develop new theories.
- Ethnography involves immersing yourself in a group or organization to understand its culture.
- Narrative research involves interpreting stories to understand how people make sense of their experiences and perceptions.
- Phenomenological research involves investigating phenomena through people’s lived experiences.
- Action research links theory and practice in several cycles to drive innovative changes.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Operationalization means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioral avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalize the variables that you want to measure.
When conducting research, collecting original data has significant advantages:
- You can tailor data collection to your specific research aims (e.g. understanding the needs of your consumers or user testing your website)
- You can control and standardize the process for high reliability and validity (e.g. choosing appropriate measurements and sampling methods )
However, there are also some drawbacks: data collection can be time-consuming, labor-intensive and expensive. In some cases, it’s more efficient to use secondary data that has already been collected by someone else, but the data might be less reliable.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
There are several methods you can use to decrease the impact of confounding variables on your research: restriction, matching, statistical control and randomization.
In restriction , you restrict your sample by only including certain subjects that have the same values of potential confounding variables.
In matching , you match each of the subjects in your treatment group with a counterpart in the comparison group. The matched subjects have the same values on any potential confounding variables, and only differ in the independent variable .
In statistical control , you include potential confounders as variables in your regression .
In randomization , you randomly assign the treatment (or independent variable) in your study to a sufficiently large number of subjects, which allows you to control for all potential confounding variables.
A confounding variable is closely related to both the independent and dependent variables in a study. An independent variable represents the supposed cause , while the dependent variable is the supposed effect . A confounding variable is a third variable that influences both the independent and dependent variables.
Failing to account for confounding variables can cause you to wrongly estimate the relationship between your independent and dependent variables.
To ensure the internal validity of your research, you must consider the impact of confounding variables. If you fail to account for them, you might over- or underestimate the causal relationship between your independent and dependent variables , or even find a causal relationship where none exists.
Yes, but including more than one of either type requires multiple research questions .
For example, if you are interested in the effect of a diet on health, you can use multiple measures of health: blood sugar, blood pressure, weight, pulse, and many more. Each of these is its own dependent variable with its own research question.
You could also choose to look at the effect of exercise levels as well as diet, or even the additional effect of the two combined. Each of these is a separate independent variable .
To ensure the internal validity of an experiment , you should only change one independent variable at a time.
No. The value of a dependent variable depends on an independent variable, so a variable cannot be both independent and dependent at the same time. It must be either the cause or the effect, not both!
You want to find out how blood sugar levels are affected by drinking diet soda and regular soda, so you conduct an experiment .
- The type of soda – diet or regular – is the independent variable .
- The level of blood sugar that you measure is the dependent variable – it changes depending on the type of soda.
Determining cause and effect is one of the most important parts of scientific research. It’s essential to know which is the cause – the independent variable – and which is the effect – the dependent variable.
In non-probability sampling , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included.
Common non-probability sampling methods include convenience sampling , voluntary response sampling, purposive sampling , snowball sampling, and quota sampling .
Probability sampling means that every member of the target population has a known chance of being included in the sample.
Probability sampling methods include simple random sampling , systematic sampling , stratified sampling , and cluster sampling .
Using careful research design and sampling procedures can help you avoid sampling bias . Oversampling can be used to correct undercoverage bias .
Some common types of sampling bias include self-selection bias , nonresponse bias , undercoverage bias , survivorship bias , pre-screening or advertising bias, and healthy user bias.
Sampling bias is a threat to external validity – it limits the generalizability of your findings to a broader group of people.
A sampling error is the difference between a population parameter and a sample statistic .
A statistic refers to measures about the sample , while a parameter refers to measures about the population .
Populations are used when a research question requires data from every member of the population. This is usually only feasible when the population is small and easily accessible.
Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable.
There are seven threats to external validity : selection bias , history, experimenter effect, Hawthorne effect , testing effect, aptitude-treatment and situation effect.
The two types of external validity are population validity (whether you can generalize to other groups of people) and ecological validity (whether you can generalize to other situations and settings).
The external validity of a study is the extent to which you can generalize your findings to different groups of people, situations, and measures.
Cross-sectional studies cannot establish a cause-and-effect relationship or analyze behavior over a period of time. To investigate cause and effect, you need to do a longitudinal study or an experimental study .
Cross-sectional studies are less expensive and time-consuming than many other types of study. They can provide useful insights into a population’s characteristics and identify correlations for further research.
Sometimes only cross-sectional data is available for analysis; other times your research question may only require a cross-sectional study to answer it.
Longitudinal studies can last anywhere from weeks to decades, although they tend to be at least a year long.
The 1970 British Cohort Study , which has collected data on the lives of 17,000 Brits since their births in 1970, is one well-known example of a longitudinal study .
Longitudinal studies are better to establish the correct sequence of events, identify changes over time, and provide insight into cause-and-effect relationships, but they also tend to be more expensive and time-consuming than other types of studies.
Longitudinal studies and cross-sectional studies are two different types of research design . In a cross-sectional study you collect data from a population at a specific point in time; in a longitudinal study you repeatedly collect data from the same sample over an extended period of time.
| Longitudinal study | Cross-sectional study |
|---|---|
| observations | Observations at a in time |
| Observes the multiple times | Observes (a “cross-section”) in the population |
| Follows in participants over time | Provides of society at a given point |
There are eight threats to internal validity : history, maturation, instrumentation, testing, selection bias , regression to the mean, social interaction and attrition .
Internal validity is the extent to which you can be confident that a cause-and-effect relationship established in a study cannot be explained by other factors.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts and meanings, use qualitative methods .
- If you want to analyze a large amount of readily-available data, use secondary data. If you want data specific to your purposes with control over how it is generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
Discrete and continuous variables are two types of quantitative variables :
- Discrete variables represent counts (e.g. the number of objects in a collection).
- Continuous variables represent measurable amounts (e.g. water volume or weight).
Quantitative variables are any variables where the data represent amounts (e.g. height, weight, or age).
Categorical variables are any variables where the data represent groups. This includes rankings (e.g. finishing places in a race), classifications (e.g. brands of cereal), and binary outcomes (e.g. coin flips).
You need to know what type of variables you are working with to choose the right statistical test for your data and interpret your results .
You can think of independent and dependent variables in terms of cause and effect: an independent variable is the variable you think is the cause , while a dependent variable is the effect .
In an experiment, you manipulate the independent variable and measure the outcome in the dependent variable. For example, in an experiment about the effect of nutrients on crop growth:
- The independent variable is the amount of nutrients added to the crop field.
- The dependent variable is the biomass of the crops at harvest time.
Defining your variables, and deciding how you will manipulate and measure them, is an important part of experimental design .
Experimental design means planning a set of procedures to investigate a relationship between variables . To design a controlled experiment, you need:
- A testable hypothesis
- At least one independent variable that can be precisely manipulated
- At least one dependent variable that can be precisely measured
When designing the experiment, you decide:
- How you will manipulate the variable(s)
- How you will control for any potential confounding variables
- How many subjects or samples will be included in the study
- How subjects will be assigned to treatment levels
Experimental design is essential to the internal and external validity of your experiment.
I nternal validity is the degree of confidence that the causal relationship you are testing is not influenced by other factors or variables .
External validity is the extent to which your results can be generalized to other contexts.
The validity of your experiment depends on your experimental design .
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research, you also have to consider the internal and external validity of your experiment.
A sample is a subset of individuals from a larger population . Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In statistics, sampling allows you to test a hypothesis about the characteristics of a population.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
Methodology refers to the overarching strategy and rationale of your research project . It involves studying the methods used in your field and the theories or principles behind them, in order to develop an approach that matches your objectives.
Methods are the specific tools and procedures you use to collect and analyze data (for example, experiments, surveys , and statistical tests ).
In shorter scientific papers, where the aim is to report the findings of a specific study, you might simply describe what you did in a methods section .
In a longer or more complex research project, such as a thesis or dissertation , you will probably include a methodology section , where you explain your approach to answering the research questions and cite relevant sources to support your choice of methods.
Ask our team
Want to contact us directly? No problem. We are always here for you.
- Email [email protected]
- Start live chat
- Call +1 (510) 822-8066
- WhatsApp +31 20 261 6040

Our team helps students graduate by offering:
- A world-class citation generator
- Plagiarism Checker software powered by Turnitin
- Innovative Citation Checker software
- Professional proofreading services
- Over 300 helpful articles about academic writing, citing sources, plagiarism, and more
Scribbr specializes in editing study-related documents . We proofread:
- PhD dissertations
- Research proposals
- Personal statements
- Admission essays
- Motivation letters
- Reflection papers
- Journal articles
- Capstone projects
Scribbr’s Plagiarism Checker is powered by elements of Turnitin’s Similarity Checker , namely the plagiarism detection software and the Internet Archive and Premium Scholarly Publications content databases .
The add-on AI detector is powered by Scribbr’s proprietary software.
The Scribbr Citation Generator is developed using the open-source Citation Style Language (CSL) project and Frank Bennett’s citeproc-js . It’s the same technology used by dozens of other popular citation tools, including Mendeley and Zotero.
You can find all the citation styles and locales used in the Scribbr Citation Generator in our publicly accessible repository on Github .
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Data Cleaning | A Guide with Examples & Steps
Data Cleaning | A Guide with Examples & Steps
Published on 6 May 2022 by Pritha Bhandari . Revised on 3 October 2022.
Data cleaning involves spotting and resolving potential data inconsistencies or errors to improve your data quality. An error is any value (e.g., recorded weight) that doesn’t reflect the true value (e.g., actual weight) of whatever is being measured.
Table of contents
Why does data cleaning matter, dirty vs clean data, accurate data, complete data, consistent data, unique data, uniform data, how do you clean data, data validation, data screening, data diagnosing, de-duplication, invalid data, missing data, frequently asked questions about data cleaning.
In quantitative research , you collect data and use statistical analyses to answer a research question. Using hypothesis testing , you find out whether your data demonstrate support for your research predictions.
Errors are often inevitable, but cleaning your data helps you minimise them. If you don’t remove or resolve these errors, you could end up with a false or invalid study conclusion.
Question : Please rate the extent to which you agree or disagree with these statements from 1 to 7.
- Positive frame: I feel well rested when I wake up in the morning.
- Negative frame: I do not feel energetic after getting 8 hours of sleep at night.
Both questions measure the same thing: how respondents feel after waking up in the morning. But the answers to negatively worded questions need to be reverse-coded before analysis so that all answers are consistently in the same direction.
Reverse coding means flipping the number scale in the opposite direction so that an extreme value (e.g., 1 or 7) means the same thing for each question.
With inaccurate or invalid data, you might make a Type I or II error in your conclusion. These types of erroneous conclusions can be practically significant with important consequences, because they lead to misplaced investments or missed opportunities.
Prevent plagiarism, run a free check.
Dirty data include inconsistencies and errors. These data can come from any part of the research process, including poor research design , inappropriate measurement materials, or flawed data entry.
Clean data meet some requirements for high quality while dirty data are flawed in one or more ways. Let’s compare dirty with clean data.
| Dirty data | Clean data |
|---|---|
| Invalid | Valid |
| Inaccurate | Accurate |
| Incomplete | Complete |
| Inconsistent | Consistent |
| Duplicate entries | Unique |
| Incorrectly formatted | Uniform |
Valid data conform to certain requirements for specific types of information (e.g., whole numbers, text, dates). Invalid data don’t match up with the possible values accepted for that observation.
Without valid data, your data analysis procedures may not make sense. It’s best to use data validation techniques to make sure your data are in the right formats before you analyse them.
In measurement, accuracy refers to how close your observed value is to the true value. While data validity is about the form of an observation, data accuracy is about the actual content.
How often do you go grocery shopping in person?
- Once a week
- Once a month
- Less than once a month
Some of the respondents select ‘biweekly’ as their answer. But this word can mean either twice a week or once every two weeks, and these are fairly different frequencies.
Complete data are measured and recorded thoroughly. Incomplete data are statements or records with missing information.
Reconstructing missing data isn’t easy to do. Sometimes, you might be able to contact a participant and ask them to redo a survey or an interview, but you might not get the answer that you would have otherwise.
Clean data are consistent across a dataset. For each member of your sample , the data for different variables should line up to make sense logically.
In data collection, you may accidentally record data from the same participant twice.
It’s important to review your data for identical entries and remove any duplicate entries in data cleaning. Otherwise, your data might be skewed.
Uniform data are reported using the same units of measure. If data aren’t all in the same units, they need to be converted to a standard measure.
Some participants respond with their monthly salary, while others report their annual salary.
Every dataset requires different techniques to clean dirty data, but you need to address these issues in a systematic way. You’ll want to conserve as much of your data as possible while also ensuring that you end up with a clean dataset.
Data cleaning is a difficult process because errors are hard to pinpoint once the data are collected. You’ll often have no way of knowing if a data point reflects the actual value of something accurately and precisely.
In practice, you may focus instead on finding and resolving data points that don’t agree or fit with the rest of your dataset in more obvious ways. These data might be missing values, outliers, incorrectly formatted, or irrelevant.
You can choose a few techniques for cleaning data based on what’s appropriate. What you want to end up with is a valid, consistent, unique, and uniform dataset that’s as complete as possible.
Data cleaning workflow
Generally, you start data cleaning by scanning your data at a broad level. You review and diagnose issues systematically and then modify individual items based on standardised procedures. Your workflow might look like this:
- Apply data validation techniques to prevent dirty data entry.
- Screen your dataset for errors or inconsistencies.
- Diagnose your data entries.
- Develop codes for mapping your data into valid values.
- Transform or remove your data based on standardised procedures.
Not all of these steps will be relevant to every dataset. You can carefully apply data cleaning techniques where necessary, with clear documentation of your processes for transparency.
By documenting your workflow, you ensure that other people can review and replicate your procedures.
Data validation involves applying constraints to make sure you have valid and consistent data. It’s usually applied even before you collect data , when designing questionnaires or other measurement materials requiring manual data entry.
Different data validation constraints help you minimise the amount of data cleaning you’ll need to do.
Data-type constraints: Values can only be accepted if they are of a certain type, such as numbers or text.
Range constraints: Values must fall within a certain range to be valid.
Mandatory constraints: A value must be entered.
Once you’ve collected your data, it’s best to create a backup of your original dataset and store it safely. If you make any mistakes in your workflow, you can always start afresh by duplicating the backup and working from the new copy of your dataset.
Data screening involves reviewing your dataset for inconsistent, invalid, missing, or outlier data. You can do this manually or with statistical methods.
Step 1: Straighten up your dataset
These actions will help you keep your data organised and easy to understand.
- Turn each variable (measure) into a column and each case (participant) into a row.
- Give your columns unique and logical names.
- Remove any empty rows from your dataset.
Step 2: Visually scan your data for possible discrepancies
Go through your dataset and answer these questions:
- Are there formatting irregularities for dates, or textual or numerical data?
- Do some columns have a lot of missing data?
- Are any rows duplicate entries?
- Do specific values in some columns appear to be extreme outliers?
Make note of these issues and consider how you’ll address them in your data cleaning procedure.
Step 3: Use statistical techniques and tables/graphs to explore data
By gathering descriptive statistics and visualisations, you can identify how your data are distributed and identify outliers or skewness.
- Explore your data visually with boxplots, scatterplots, or histograms
- Check whether your data are normally distributed
- Create summary (descriptive) statistics for each variable
- Summarise your quantitative data in frequency tables
You can get a rough idea of how your quantitative variable data are distributed by visualising them. Boxplots and scatterplots can show how your data are distributed and whether you have any extreme values. It’s important to check whether your variables are normally distributed so that you can select appropriate statistical tests for your research.
If your mean , median , and mode all differ from each other by a lot, there may be outliers in the dataset that you should look into.
After a general overview, you can start getting into the nitty-gritty of your dataset. You’ll need to create a standard procedure for detecting and treating different types of data.
Without proper planning, you might end up cherry-picking only some data points to clean, leading to a biased dataset.
Here we’ll focus on ways to deal with common problems in dirty data:
- Duplicate data
- Missing values
De-duplication means detecting and removing any identical copies of data, leaving only unique cases or participants in your dataset.
If duplicate data are left in the dataset, they will bias your results. Some participants’ data will be weighted more heavily than others’.
Using data standardisation , you can identify and convert data from varying formats into a uniform format.
Unlike data validation, you can apply standardisation techniques to your data after you’ve collected it. This involves developing codes to convert your dirty data into consistent and valid formats.
Data standardisation is helpful if you don’t have data constraints at data entry or if your data have inconsistent formats.
These are some of the responses:
String-matching methods
To standardise inconsistent data, you can use strict or fuzzy string-matching methods to identify exact or close matches between your data and valid values.
A string is a sequence of characters. You compare your data strings to the valid values you expect to obtain and then remove or transform the strings that don’t match.
Strict string-matching: Any strings that don’t match the valid values exactly are considered invalid.
In this case, only 3 out of 5 values will be accepted with strict matching.
Fuzzy string-matching: Strings that closely or approximately match valid values are recognised and corrected.
For closely matching strings, your program checks how many edits are needed to change the string into a valid value, and if the number of edits is small enough, it makes those changes.
All five values will be accepted with fuzzy string-matching.
After matching, you can transform your text data into numbers so that all values are consistently formatted.
Fuzzy string-matching is generally preferable to strict string-matching because more data are retained.
In any dataset, there’s usually some missing data . These cells appear blank in your spreadsheet.
Missing data can come from random or systematic causes.
- Random missing data include data entry errors, inattention errors, or misreading of measures.
- Non-random missing data result from confusing, badly designed, or inappropriate measurements or questions.
Dealing with missing data
Your options for tackling missing data usually include:
- Accepting the data as they are
- Removing the case from analyses
- Recreating the missing data
Random missing data are usually left alone, while non-random missing data may need removal or replacement.
With deletion , you remove participants with missing data from your analyses. But your sample may become smaller than intended, so you might lose statistical power .
Alternatively, you can use imputation to replace a missing value with another value based on a reasonable estimate. You use other data to replace the missing value for a more complete dataset.
It’s important to apply imputation with caution, because there’s a risk of bias or inaccuracy.
Outliers are extreme values that differ from most other data points in a dataset. Outliers can be true values or errors.
True outliers should always be retained, because these just represent natural variations in your sample. For example, athletes training for a 100-metre Olympic sprint have much higher speeds than most people in the population. Their sprint speeds are natural outliers.
Outliers can also result from measurement errors, data entry errors, or unrepresentative sampling. For example, an extremely low sprint time could be recorded if you misread the timer.
Detecting outliers
Outliers are always at the extreme ends of any variable dataset.
You can use several methods to detect outliers:
- Sorting your values from low to high and checking minimum and maximum values
- Visualising your data in a boxplot and searching for outliers
- Using statistical procedures to identify extreme values
Dealing with outliers
Once you’ve identified outliers, you’ll decide what to do with them in your dataset. Your main options are retaining or removing them.
In general, you should try to accept outliers as much as possible unless it’s clear that they represent errors or bad data.
Data cleaning involves spotting and resolving potential data inconsistencies or errors to improve your data quality. An error is any value (e.g., recorded weight) that doesn’t reflect the true value (e.g., actual weight) of something that’s being measured.
In this process, you review, analyse, detect, modify, or remove ‘dirty’ data to make your dataset ‘clean’. Data cleaning is also called data cleansing or data scrubbing.
Data cleaning is necessary for valid and appropriate analyses. Dirty data contain inconsistencies or errors , but cleaning your data helps you minimise or resolve these.
Without data cleaning, you could end up with a Type I or II error in your conclusion. These types of erroneous conclusions can be practically significant with important consequences, because they lead to misplaced investments or missed opportunities.
Data cleaning takes place between data collection and data analyses. But you can use some methods even before collecting data.
For clean data, you should start by designing measures that collect valid data. Data validation at the time of data entry or collection helps you minimize the amount of data cleaning you’ll need to do.
After data collection, you can use data standardisation and data transformation to clean your data. You’ll also deal with any missing values, outliers, and duplicate values.
Clean data are valid, accurate, complete, consistent, unique, and uniform. Dirty data include inconsistencies and errors.
Dirty data can come from any part of the research process, including poor research design , inappropriate measurement materials, or flawed data entry.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2022, October 03). Data Cleaning | A Guide with Examples & Steps. Scribbr. Retrieved 9 September 2024, from https://www.scribbr.co.uk/research-methods/data-cleaning/
Is this article helpful?

Pritha Bhandari
Other students also liked, data collection methods | step-by-step guide & examples, what is quantitative research | definition & methods, a quick guide to experimental design | 5 steps & examples.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Working with Data
7 Data Cleaning During the Research Data Management Process
Lucia Costanzo
Learning Outcomes
By the end of this chapter you should be able to:
- Describe why it is important to clean your data.
- Recall the common data cleaning tasks.
- Implement common data cleaning tasks using OpenRefine.
What Is Data Cleaning?
You may have heard of the 80/20 dilemma: Most researchers spend 80% of their time finding, cleaning, and reorganizing huge amounts of data and only 20% of their time on actual data analysis.
When starting a research project, you will use either primary data generated from your own experiment or secondary data from another researcher’s experiment. Once you obtain data to answer your research question(s), you’ll need time to explore and understand it. The data may be in a format which will not allow for easy analysis. During the data cleaning phase, you’ll use Research Data Management (RDM) practices. The data cleaning process can be time consuming and tedious but is crucial to ensure accurate and high-quality research.
Data cleaning may seem to be an obvious step, but it is where most researchers struggle. George Fuechsel, an IBM programmer and instructor, coined the phrase “garbage in, garbage out” (Lidwell et al, 2010) to remind his students that a computer processes what it is given — whether the information is good or bad. The same applies to researchers; no matter how good your methods are, the analysis relies on the quality of the data. That is, the results and conclusions of a research study will be as reliable as the data that you used.
Using data that have been cleaned ensures you won’t waste time on unnecessary analysis.
Six Core Data Cleaning and Preparation Activities
Data cleaning and preparation can be distilled into six core activities: discovering, structuring, cleaning, enriching, validating, and publishing. These are conducted throughout the research project to keep data organized. Let’s take a closer look at these activities.
1. Discovering Data
The important step of discovering what’s in your data is often referred to as Exploratory Data Analysis (EDA) . The concept of EDA was developed in the late 1970s by American mathematician John Tukey. According to a memoir, “Tukey often likened EDA to detective work. The role of the data analyst is to listen to the data in as many ways as possible until a plausible ‘story’ of the data is apparent” (Behrens, 1997). EDA is an approach used to better understand the data through quantitative and graphical methods.
Quantitative methods summarize variable characteristics by using measures of central tendency, including mean, median, and mode. The most common is mean. Measures of spread indicate how far from the center one is likely to find data points. Variance, standard deviation, range, and interquartile range are all measures of spread. Quantitatively, the shape of the distribution can be evaluated using skewness, which is a measure of asymmetry. Histograms, boxplots, and sometimes stem-and-leaf plots are used for quick visual inspections of each variable for central tendency, spread, modality, shape, and outliers.
Exploring data through EDA techniques supports discovery of underlying patterns and anomalies, helps frame hypotheses, and verifies assumptions related to analysis. Now let’s take a closer look at structuring the data.
2. Structuring Data
Depending on the research question(s), you may need to set up the data in different ways for different types of analyses. Repeated measures data, where each experimental unit or subject is measured at several points in time or at different conditions, can be used to illustrate this.
In Figure 1, researchers might be investigating the effect of a morning breakfast program on Grade 6 students and want to collect test scores at three time points, such as the pre- (T1), mid- (T2), and post-morning (T3) periods of the breakfast program. Note that the same students are in each group, with each student being measured at different points in time. Each measurement is a snapshot in time during the study. There are two different ways to structure repeated measures data: long and wide formats.

Table 1 shows data structured in long format, with each student in the study represented by three rows of data, one for each time point for which test scores were collected. Looking at the first row, Student One at Timepoint 1 (before the breakfast program) scored 50 on the test. In the second row, Student One at Timepoint 2 (midway through the breakfast program) scored higher on the test, at 65. And in the third row, Student One at Timepoint 3 (after the program) scored 80.
The wide format, shown in Table 2, uses one row for each observation or participant, and each measurement or response is in a separate column. In wide format, each student’s repeated test scores are in a row, and each test result for the student is in a column. Looking at the first row, Student One scored 50 on the test before the breakfast program, then scored 65 on the test midway through the breakfast program, and achieved 80 on the test after the program.
So, a long data format uses multiple rows for each observation or participant, while wide data formats use one row per observation. How you choose to structure your data (long or wide) will depend on the model or statistical analysis you’re undertaking. It is possible you may need to structure your data in both long and wide data formats to achieve your analysis goals.

Structuring is an important core data cleaning and preparation activity that focuses on reshaping data for a particular statistical analysis. Data can contain irregularities and inconsistencies, which can impact the accuracy of the researcher’s models. Let’s take a closer look at cleaning the data, so that your analysis can provide accurate results.
3. Cleaning Data
Data cleaning is central to ensuring you have high-quality data for analysis. The following nine tips address a range of commonly encountered data cleaning issues using practical examples.
Tip 1: Spell Check

Spell checkers can also be used to standardize names. For example, if a dataset contained entries for “University of Guelph” and “UOG” and “U of G” and “Guelph University” (Table 3), each spelling would be counted as a different school. It doesn’t matter which spelling you use, just make sure it’s standard throughout the dataset.
Tip 01 Exercise: Spell Check
Go through Table 3 and standardize the name as “University of Guelph” in the SCHOOL column.
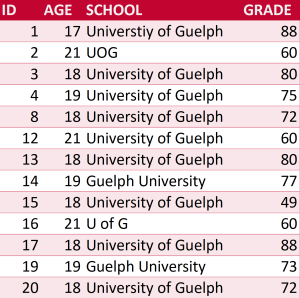
View Solutions for answers. Data files for the exercises in this chapter are available in the Borealis archive for this text.
Tip 2: Duplicates

Tip 02: Exercise: Duplicates
Go through Table 4 and delete the duplicate observations.
HINT: If using Excel, look for and use the ‘Duplicate Values’ feature.
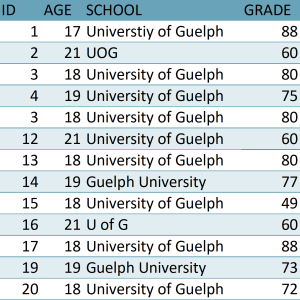
View Solutions for answers.
Tip 3: Find and Replace

Tip 03 Exercise: Find and Replace
Go through Table 5. Find and replace all instances of “ST” and “st” with “Street” in the LOCATION column.
HINT: Use caution with global Find and Replace functions. In the example shown below, instances of ‘St’ or ‘st’ that do NOT indicate ‘Street’ (e.g. ‘Steffler’ and ‘First’) will be erroneously replaced. Avoid such unwanted changes by strategically including a leading space in the string you are searching for (so, ‘spaceSt’). Experiment with the ‘match case’ feature as well, if available. Always keep a backup of your unchanged data in case things go awry.
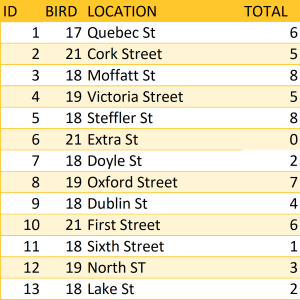
Tip 4: Letter Case

Tip 04 Exercise: Letter Case
Convert text in the NAME column in Table 6 to proper case. Then convert text in the EMAIL column to lowercase.
HINT: If using Excel, look for UPPER, LOWER, and PROPER functions.

Tip 5: Spaces and Non-Printing Characters

Tip 6: Numbers and Signs
There are two issues to watch for:
- data may include text
- negative signs may not be standardized

Numbers can be formatted in different ways, especially with finance data. For example, negative values can be represented with a hyphen or placed inside parentheses or are sometimes highlighted in red. Not all these negative values will be correctly read by a computer, particularly the colour option. When cleaning data, choose and apply a clear and consistent approach to formatting all negative values. A common choice is to use a negative sign.
Tip 06 Exercise: Numbers and Signs
Create a new column named JUVENILE_NUM as part of Table 7. Record a value of 0 in the JUVENILE_NUM column when “no” appears in the JUVENILE column. Record a value of 1 in the JUVENILE_NUM column when “yes” appears in the JUVENILE column.
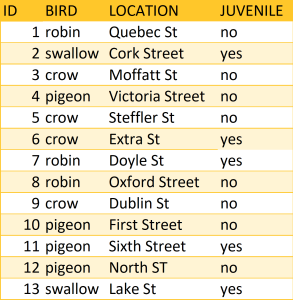
Tip 7: Dates and Time

Tip 8: Merge and Split Columns

Tip 08 Exercise: Merge and Split Columns
In Table 8, split the NAME column into two, for first and last names.
HINT: If using Excel, look for functions to “Combine text from two or more cells into one cell” and “Split text into different columns.”

Tip 9: Subset Data

Tip o9 Exercise: Subset Data
Create a subset of data in Table 9 to include only observations of juveniles (JUVENILE = 1).
HINT: As always, it is important to keep a copy of your original data.
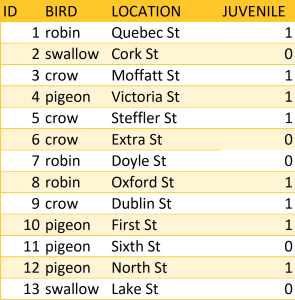
Cleaning data is an important activity that focuses on removing inconsistencies and errors, which can impact the accuracy of models. The process of cleaning data also provides an opportunity to look closer at the data to determine whether transformations, recoding, or linking additional data is desired.
4. Enriching Data
Sometimes a dataset may not have all the information needed to answer the research question. This means you need to find other datasets and merge them into the current one. This can be as easy as adding geographical data, such as a postal code or longitude and latitude coordinates; or demographic data, such as income, marital status, education, age, or number of children. Enriching data improves the potential for finding fuller answers to the research question(s) at hand.
It’s also important to verify data quality and consistency within a dataset. Let’s take a closer look at validating data, so that the models provide accurate results.
5. Validating Data
Data validation is vital to ensure data are clean, correct, and useful. Remember the adage by Fuechsel — “garbage in, garbage out.” If the incorrect data are fed into a statistical analysis, then the resulting answers will be incorrect too. A computer program doesn’t have common sense and will process the data it is given, good or bad, and while data validation does take time, it helps maximize the potential for data to respond to the research question(s) at hand. Some common data validation checks include the following:
- Checking column data types and underlying data to make sure they’re what they are supposed to be. For example, a date variable may need to be converted from a string to a date format. If in doubt, convert the value to a string and it can be changed later if need be.
- Examining the scope and accuracy of data by reviewing key aggregate functions, like sum, count, min, max, mean, or other related operations. This is particularly important in the context of actual data analysis. Statistics Canada, for example, will code missing values for age using a number well beyond the scope of a human life in years (e.g. using a number like 999). If these values are inadvertently included in your analysis (due to ‘missing values’ not being explicitly declared) any results involving age will be in error. Calculating and reviewing mean, minimum, maximum, etc. will help identify and avoid such errors.
- Ensuring variables have been standardized. For example, when recording latitude and longitude coordinates for locations in North America, check that the latitude coordinates are positive and the longitude coordinates are negative to avoid mistakenly referring to places on the other side of the planet.
It’s important to validate data to ensure quality and consistency. Once all research questions have been answered, it’s good practice to share the clean data with other researchers where confidentiality and other restrictions allow. Let’s take a closer look at publishing data, so that it can be shared with other researchers.
6. Publishing Data
Having made the effort to clean and validate your data and to investigate whatever research questions you set out to answer, it is a key RDM best practice to ensure your data are available for appropriate use by others. This goal is embodied by the FAIR principles covered elsewhere in this textbook, which aim to make data Findable, Accessible, Interoperable , and Reusable. Publishing data helps achieve this goal.
While the best format for collecting, managing, and analyzing data may involve proprietary software, data should be converted to nonproprietary formats for publication. Generally, this will involve plain text. For simple spreadsheets, converting data to CSV (comma separated values) may be best, while more complex data structures may be best suited to XML. This will guard against proprietary formats that quickly become obsolete and will ensure data are more universally available to other researchers going forward. This is discussed more in chapter 9, “ A Glimpse Into the Fascinating World of File Formats and Metadata .”
If human subject data or other private information is involved, you may need to consider anonymizing or de-identifying the data (which is covered in chapter 13, “ Sensitive Data ”) . Keep in mind that removing explicit reference to individuals may not be enough to ensure they cannot be identified. If it’s impossible to guard against unwanted disclosure of private information, you may need to publish a subset of the data that is safe for public exposure.
For other researchers to make use of the data, include documentation and metadata , including documentation at the levels of the project, data files, and data elements. A data dictionary outlines the names, definitions, and attributes of the elements in a dataset and is discussed more in c hapter 10 . You should also document any scripts or methods that have been developed for analyzing the data.
Data Cleaning Software
OpenRefine ( https://openrefine.org/ ) is a powerful data manipulation tool that cleans, reshapes, and batch edits messy and unstructured data. It works best with data in simple tabular formats , like spreadsheets (CSV), or tab-separated values files (TSV) , to name a few. OpenRefine is as easy to use as an Excel spreadsheet and has powerful database functions, like Microsoft Access. It is a desktop application that uses a browser as a graphical interface. All data processing is done locally on your computer. When using OpenRefine to clean and transform data, users can facet, cluster, edit cells, reconcile, and use extended web services to convert a dataset to a more structured format. There’s no cost to use this open source software and the source code is freely available, along with modifications by others. There are other tools available for data cleaning, but these are often costly, and OpenRefine is extensively used in the RDM field. If you choose to use other data cleaning software, always check to see if your data remain on your computer or are sent elsewhere for processing.
Exercise: Clean and Prepare Data for Analysis using OpenRefine
Go to the “ Cleaning Data with OpenRefine ” tutorial and download the Powerhouse museum dataset, consisting of detailed metadata on the collection objects, including title, description, several categories the item belongs to, provenance information, and a persistent link to the object on the museum website. You will step through several data cleaning tasks.
We have covered the six core data cleaning and preparation activities of discovering, structuring, cleaning, enriching, validating, and publishing. By applying these important RDM practices, your data will be complete, documented, and accessible to you and future researchers. You will satisfy grant, journal, and/or funder requirements, raise your profile as a researcher, and meet the growing data-sharing expectations of the research community. RDM practices like data cleaning are crucial to ensure accurate and high-quality research.
Key Takeaways
- Data cleaning is an important task that improves the accuracy and quality of data ahead of data analysis.
- Six core data cleaning tasks are discovering, structuring, cleaning, enriching, validating, and publishing.
- OpenRefine is a powerful data manipulation tool that cleans, reshapes, and batch edits messy and unstructured data.
Reference List
Behrens, J. T. (1997). Principles and procedures of exploratory data analysis. Psychological Methods , 2 (2), 131.
Lidwell, W., Holden, K., & Butler, J. (2010). Universal principles of design, revised and updated: 125 ways to enhance usability, influence perception, increase appeal, make better design decisions, and teach through design . Rockport Publishers.
a term that describes all the activities that researchers perform to structure, organize, and maintain research data before, during, and after the research process.
the process of employing six core activities: discovering, structuring, cleaning, enriching, validating, and publishing data.
a process used to explore, analyze, and summarize datasets through quantitative and graphical methods. EDA makes it easier to find patterns and discover irregularities and inconsistencies in the dataset.
guiding principles to ensure that machines and humans can easily discover, access, interoperate, and properly reuse information. They ensure that information is findable, accessible, interoperable, and reusable.
interoperability requires that data and metadata use formalized, accessible, and widely used formats. For example, when saving tabular data, it is recommended to use a .csv file over a proprietary file such as .xlsx (Excel). A .csv file can be opened and read by more programs than an .xlsx file.
a delimited text file that uses a comma to separate values within a data record.
data about data; data that define and describe the characteristics of other data.
an open source data manipulation tool that cleans, reshapes, and batch edits messy and unstructured data.
a format in which information are entered into a table in rows and columns.
when software is open source, users are permitted to inspect, use, modify, improve, and redistribute the underlying code. Many programmers use the MIT License when publishing their code, which includes the requirement that all subsequent iterations of the software include the MIT license as well.
About the author
name: Lucia Costanzo
Lucia Costanzo is the Research Data Management (RDM) Librarian at the University of Guelph. She recently completed a secondment at the Digital Research Alliance of Canada (the Alliance) as the Research Intelligence and Assessment Coordinator. As part of this role, Lucia coordinated the activities of the Research Intelligence Expert Group, which included informing and advising the Alliance RDM Team and Alliance management on emerging developments and directions, both nationally and internationally, in RDM and broader Digital Research Infrastructure ecosystems. Before the secondment, Lucia actively supported, enabled, and contributed to the learning and research process on campus for over twenty years at the University of Guelph. Email: [email protected] | ORCID: 0000-0003-4785-660X
Research Data Management in the Canadian Context Copyright © 2023 by Lucia Costanzo is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Digital Object Identifier (DOI)
https://doi.org/10.5206/IERZ1050
Share This Book
Loading metrics
Open Access
Policy Forum
Policy Forum articles provide a platform for health policy makers from around the world to discuss the challenges and opportunities in improving health care to their constituencies.
See all article types »
Data Cleaning: Detecting, Diagnosing, and Editing Data Abnormalities
* To whom correspondence should be addressed. E-mail: [email protected]
- Solveig Argeseanu Cunningham,
- Roger Eeckels,
- Kobus Herbst
- Jan Van den Broeck,
- Solveig Argeseanu Cunningham,
- Roger Eeckels,
Published: September 6, 2005
- https://doi.org/10.1371/journal.pmed.0020267
- Reader Comments
Citation: Van den Broeck J, Argeseanu Cunningham S, Eeckels R, Herbst K (2005) Data Cleaning: Detecting, Diagnosing, and Editing Data Abnormalities. PLoS Med 2(10): e267. https://doi.org/10.1371/journal.pmed.0020267
Copyright: © 2005 Van den Broeck et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Competing interests: The authors have declared that no competing interests exist.
In clinical epidemiological research, errors occur in spite of careful study design, conduct, and implementation of error-prevention strategies. Data cleaning intends to identify and correct these errors or at least to minimize their impact on study results. Little guidance is currently available in the peer-reviewed literature on how to set up and carry out cleaning efforts in an efficient and ethical way. With the growing importance of Good Clinical Practice guidelines and regulations, data cleaning and other aspects of data handling will emerge from being mainly gray-literature subjects to being the focus of comparative methodological studies and process evaluations. We present a brief summary of the scattered information, integrated into a conceptual framework aimed at assisting investigators with planning and implementation. We recommend that scientific reports describe data-cleaning methods, error types and rates, error deletion and correction rates, and differences in outcome with and without remaining outliers.
The History of Data Cleaning
With Good Clinical Practice guidelines being adopted and regulated in more and more countries, some important shifts in clinical epidemiological research practice can be expected. One of the expected developments is an increased emphasis on standardization, documentation, and reporting of data handling and data quality. Indeed, in scientific tradition, especially in academia, study validity has been discussed predominantly with regard to study design, general protocol compliance, and the integrity and experience of the investigator. Data handling, although having an equal potential to affect the quality of study results, has received proportionally less attention. As a result, even though the importance of data-handling procedures is being underlined in good clinical practice and data management guidelines [ 1–3 ], there are important gaps in knowledge about optimal data-handling methodologies and standards of data quality. The Society for Clinical Data Management, in their guidelines for good clinical data management practices, states: “Regulations and guidelines do not address minimum acceptable data quality levels for clinical trial data. In fact, there is limited published research investigating the distribution or characteristics of clinical trial data errors. Even less published information exists on methods of quantifying data quality” [ 4 ].
Data cleaning is emblematic of the historical lower status of data quality issues and has long been viewed as a suspect activity, bordering on data manipulation. Armitage and Berry [ 5 ] almost apologized for inserting a short chapter on data editing in their standard textbook on statistics in medical research. Nowadays, whenever discussing data cleaning, it is still felt to be appropriate to start by saying that data cleaning can never be a cure for poor study design or study conduct. Concerns about where to draw the line between data manipulation and responsible data editing are legitimate. Yet all studies, no matter how well designed and implemented, have to deal with errors from various sources and their effects on study results. This problem occurs as much to experimental as to observational research and clinical trials [ 6 , 7 ]. Statistical societies recommend that description of data cleaning be a standard part of reporting statistical methods [ 8 ]. Exactly what to report and under what circumstances remains mostly unanswered. In practice, it is rare to find any statements about data-cleaning methods or error rates in medical publications.
Although certain aspects of data cleaning such as statistical outlier detection and handling of missing data have received separate attention [ 9–18 ], the data-cleaning process, as a whole, with all its conceptual, organizational, logistical, managerial, and statistical-epidemiological aspects, has not been described or studied comprehensively. In statistical textbooks and non-peer-reviewed literature, there is scattered information, which we summarize in this paper, using the concepts and definitions shown in Box 1 .
Box 1. Terms Related to Data Cleaning
Data cleaning: Process of detecting, diagnosing, and editing faulty data.
Data editing: Changing the value of data shown to be incorrect.
Data flow: Passage of recorded information through successive information carriers.
Inlier: Data value falling within the expected range.
Outlier: Data value falling outside the expected range.
Robust estimation: Estimation of statistical parameters, using methods that are less sensitive to the effect of outliers than more conventional methods.
The complete process of quality assurance in research studies includes error prevention, data monitoring, data cleaning, and documentation. There are proposed models that describe total quality assurance as an integrated process [ 19 ]. However, we concentrate here on data cleaning and, as a second aim of the paper, separately describe a framework for this process. Our focus is primarily on medical research and on practical relevance for the medical investigator.
Data Cleaning as a Process
Data cleaning deals with data problems once they have occurred. Error-prevention strategies can reduce many problems but cannot eliminate them. We present data cleaning as a three-stage process, involving repeated cycles of screening, diagnosing, and editing of suspected data abnormalities. Figure 1 shows these three steps, which can be initiated at three different stages of a study. Many data errors are detected incidentally during study activities other than data cleaning. However, it is more efficient to detect errors by actively searching for them in a planned way. It is not always immediately clear whether a data point is erroneous. Many times, what is detected is a suspected data point or pattern that needs careful examination. Similarly, missing values require further examination. Missing values may be due to interruptions of the data flow or the unavailability of the target information. Hence, predefined rules for dealing with errors and true missing and extreme values are part of good practice. One can screen for suspect features in survey questionnaires, computer databases, or analysis datasets. In small studies, with the investigator closely involved at all stages, there may be little or no distinction between a database and an analysis dataset.
- PPT PowerPoint slide
- PNG larger image
- TIFF original image
(Illustration: Giovanni Maki)
https://doi.org/10.1371/journal.pmed.0020267.g001
The diagnostic and treatment phases of data cleaning require insight into the sources and types of errors at all stages of the study, during as well as after measurement. The concept of data flow is crucial in this respect. After measurement, research data undergo repeated steps of being entered into information carriers, extracted, transferred to other carriers, edited, selected, transformed, summarized, and presented. It is important to realize that errors can occur at any stage of the data flow, including during data cleaning itself. Table 1 illustrates some of the sources and types of errors possible in a large questionnaire survey. Most problems are due to human error.
https://doi.org/10.1371/journal.pmed.0020267.t001
Inaccuracy of a single measurement and data point may be acceptable, and related to the inherent technical error of the measurement instrument. Hence, data cleaning should focus on those errors that are beyond small technical variations and that constitute a major shift within or beyond the population distribution. In turn, data cleaning must be based on knowledge of technical errors and expected ranges of normal values.
Some errors deserve priority, but which ones are most important is highly study-specific. In most clinical epidemiological studies, errors that need to be cleaned, at all costs, include missing sex, sex misspecification, birth date or examination date errors, duplications or merging of records, and biologically impossible results. For example, in nutrition studies, date errors lead to age errors, which in turn lead to errors in weight-for-age scoring and, further, to misclassification of subjects as under- or overweight.
Errors of sex and date are particularly important because they contaminate derived variables. Prioritization is essential if the study is under time pressures or if resources for data cleaning are limited.
Screening Phase
When screening data, it is convenient to distinguish four basic types of oddities: lack or excess of data; outliers, including inconsistencies; strange patterns in (joint) distributions; and unexpected analysis results and other types of inferences and abstractions ( Table 1 ). Screening methods need not only be statistical. Many outliers are detected by perceived nonconformity with prior expectations, based on the investigator's experience, pilot studies, evidence in the literature, or common sense. Detection may even happen during article review or after publication.
What can be done to make screening objective and systematic? To allow the researcher to understand the data better, it should be examined with simple descriptive tools. Standard statistical packages or even spreadsheets make this easy to do [ 20 , 21 ]. For identifying suspect data, one can first predefine expectations about normal ranges, distribution shapes, and strength of relationships [ 22 ]. Second, the application of these criteria can be planned beforehand, to be carried out during or shortly after data collection, during data entry, and regularly thereafter. Third, comparison of the data with the screening criteria can be partly automated and lead to flagging of dubious data, patterns, or results.
A special problem is that of erroneous inliers, i.e., data points generated by error but falling within the expected range. Erroneous inliers will often escape detection. Sometimes, inliers are discovered to be suspect if viewed in relation to other variables, using scatter plots, regression analysis, or consistency checks [ 23 ]. One can also identify some by examining the history of each data point or by remeasurement, but such examination is rarely feasible. Instead, one can examine and/or remeasure a sample of inliers to estimate an error rate [ 24 ]. Useful screening methods are listed in Box 2 .
Box 2. Screening Methods
- Checking of questionnaires using fixed algorithms.
- Validated data entry and double data entry.
- Browsing of data tables after sorting.
- Printouts of variables not passing range checks and of records not passing consistency checks.
- Graphical exploration of distributions: box plots, histograms, and scatter plots.
- Plots of repeated measurements on the same individual, e.g., growth curves.
- Frequency distributions and cross-tabulations.
- Summary statistics.
- Statistical outlier detection.
Diagnostic Phase
In this phase, the purpose is to clarify the true nature of the worrisome data points, patterns, and statistics. Possible diagnoses for each data point are as follows: erroneous, true extreme, true normal (i.e, the prior expectation was incorrect), or idiopathic (i.e., no explanation found, but still suspect). Some data points are clearly logically or biologically impossible. Hence, one may predefine not only screening cutoffs as described above (soft cutoffs), but also cutoffs for immediate diagnosis of error (hard cutoffs) [ 10 ]. Figure 2 illustrates this method. Sometimes, suspected errors will fall in between the soft and hard cutoffs, and diagnosis will be less straightforward. In these cases, it is necessary to apply a combination of diagnostic procedures.
https://doi.org/10.1371/journal.pmed.0020267.g002
One procedure is to go to previous stages of the data flow to see whether a value is consistently the same. This requires access to well-archived and documented data with justifications for any changes made at any stage. A second procedure is to look for information that could confirm the true extreme status of an outlying data point. For example, a very low score for weight-for-age (e.g., −6 Z -scores) might be due to errors in the measurement of age or weight, or the subject may be extremely malnourished, in which case other nutritional variables should also have extremely low values. Individual patients' reports with accumulated information on related measurements are helpful for this purpose. This type of procedure requires insight into the coherence of variables in a biological or statistical sense. Again, such insight is usually available before the study and can be used to plan and program data cleaning. A third procedure is to collect additional information, e.g., question the interviewer/measurer about what may have happened and, if possible, repeat the measurement. Such procedures can only happen if data cleaning starts soon after data collection, and sometimes remeasuring is only valuable very shortly after the initial measurement. In longitudinal studies, variables are often measured at specific ages or follow-up times. With such designs, the possibility of remeasuring or obtaining measurements for missing data will often be limited to predefined allowable intervals around the target times. Such intervals can be set wider if the analysis foresees using age or follow-up time as a continuous variable.
Finding an acceptable value does not always depend on measuring or remeasuring. For some input errors, the correct value is immediately obvious, e.g., if values of infant length are noted under head circumference and vice versa. This example again illustrates the usefulness of the investigator's subject-matter knowledge in the diagnostic phase. Substitute code values for missing data should be corrected before analysis.
During the diagnostic phase, one may have to reconsider prior expectations and/or review quality assurance procedures. The diagnostic phase is labor intensive and the budgetary, logistical, and personnel requirements are typically underestimated or even neglected at the study design stage. How much effort must be spent? Cost-effectiveness studies are needed to answer this question. Costs may be lower if the data-cleaning process is planned and starts early in data collection. Automated query generation and automated comparison of successive datasets can be used to lower costs and speed up the necessary steps.
Treatment Phase
After identification of errors, missing values, and true (extreme or normal) values, the researcher must decide what to do with problematic observations. The options are limited to correcting, deleting, or leaving unchanged. There are some general rules for which option to choose. Impossible values are never left unchanged, but should be corrected if a correct value can be found, otherwise they should be deleted. For biological continuous variables, some within-subject variation and small measurement variation is present in every measurement. If a remeasurement is done very rapidly after the initial one and the two values are close enough to be explained by these small variations alone, accuracy may be enhanced by taking the average of both as the final value.
What should be done with true extreme values and with values that are still suspect after the diagnostic phase? The investigator may wish to further examine the influence of such data points, individually and as a group, on analysis results before deciding whether or not to leave the data unchanged. Statistical methods exist to help evaluate the influence of such data points on regression parameters. Some authors have recommended that true extreme values should always stay in the analysis [ 25 ]. In practice, many exceptions are made to that rule. The investigator may not want to consider the effect of true extreme values if they result from an unanticipated extraneous process. This becomes an a posteriori exclusion criterion and the data points should be reported as “excluded from analysis”. Alternatively, it may be that the protocol-prescribed exclusion criteria were inadvertently not applied in some cases [ 26 ].
Data cleaning often leads to insight into the nature and severity of error-generating processes. The researcher can then give methodological feedback to operational staff to improve study validity and precision of outcomes. It may be necessary to amend the study protocol, regarding design, timing, observer training, data collection, and quality control procedures. In extreme cases, it may be necessary to restart the study. Programming of data capture, data transformations, and data extractions may need revision, and the analysis strategy should be adapted to include robust estimation or to do separate analyses with and without remaining outliers and/or with and without imputation.
Data Cleaning as a Study- Specific Process
The sensitivity of the chosen statistical analysis method to outlying and missing values can have consequences in terms of the amount of effort the investigator wants to invest to detect and remeasure. It also influences decisions about what to do with remaining outliers (leave unchanged, eliminate, or weight during analysis) and with missing data (impute or not) [ 27–31 ]. Study objectives codetermine the required precision of the outcome measures, the error rate that is acceptable, and, therefore, the necessary investment in data cleaning.
Longitudinal studies necessitate checking the temporal consistency of data. Plots of serial individual data such as growth data or repeated measurements of categorical variables often show a recognizable pattern from which a discordant data point clearly stands out. In clinical trials, there may be concerns about investigator bias resulting from the close data inspections that occur during cleaning, so that examination by an independent expert may be needed.
In small studies, a single outlier will have a greater distorting effect on the results. Some screening methods such as examination of data tables will be more effective, whereas others, such as statistical outlier detection, may become less valid with smaller samples. The volume of data will be smaller; hence, the diagnostic phase can be cheaper and the whole procedure more complete. Smaller studies usually involve fewer people, and the steps in the data flow may be fewer and more straightforward, allowing fewer opportunities for errors.
In intervention studies with interim evaluations of safety or efficacy, it is of particular importance to have reliable data available before the evaluations take place. There is a need to initiate and maintain an effective data-cleaning process from the start of the study.
Documentation and Reporting
Good practice guidelines for data management require transparency and proper documentation of all procedures [ 1–4 , 30 ]. Data cleaning, as an essential aspect of quality assurance and a determinant of study validity, should not be an exception. We suggest including a data-cleaning plan in study protocols. This plan should include budget and personnel requirements, prior expectations used to screen suspect data, screening tools, diagnostic procedures used to discern errors from true values, and the decision rules that will be applied in the editing phase. Proper documentation should exist for each data point, including differential flagging of types of suspected features, diagnostic information, and information on type of editing, dates, and personnel involved.
In large studies, data-monitoring and safety committees should receive detailed reports on data cleaning, and procedural feedbacks on study design and conduct should be submitted to a study's steering and ethics committees. Guidelines on statistical reporting of errors and their effect on outcomes in large surveys have been published [ 31 ]. We recommend that medical scientific reports include data-cleaning methods. These methods should include error types and rates, at least for the primary outcome variables, with the associated deletion and correction rates, justification for imputations, and differences in outcome with and without remaining outliers [ 25 ].
Acknowledgments
This work was generously supported by the Wellcome Trust (grants 063009/B/00/Z and GR065377).
- 1. International Conference on Harmonization (1997) Guideline for good clinical practice: ICH harmonized tripartite guideline. Geneva: International Conference on Harmonization. Available: http://www.ich.org/MediaServer.jser?@_ID=482&@_MODE=GLB . Accessed 29 July 2005.
- 2. Association for Clinical Data Management (2003) ACDM guidelines to facilitate production of a data handling protocol. St. Albans (United Kingdom): Association for Clinical Data Management. Available: http://www.acdm.org.uk/files/pubs/DHP%20Guidelines.doc . Accessed 28 July 2005.
- 3. Food and Drug Administration (1999) Guidance for industry: Computerized systems used in clinical trials. Washington (D. C.): Food and Drug Administration. Available: http://www.fda.gov/ora/compliance_ref/bimo/ffinalcct.htm . Accessed 28 July 2005.
- 4. Society for Clinical Data Management (2003) Good clinical data management practices, version 3.0. Milwaukee (Wisconsin): Society for Clinical Data Management. Available: http://www.scdm.org/GCDMP . Accessed 28 July 2005.
- 5. Armitage P, Berry G (1987) Statistical methods in medical research, 2nd ed. Oxford: Blackwell Scientific Publications. 559 p.
- View Article
- Google Scholar
- 8. American Statistical Association (1999) Ethical guidelines for statistical practice. Alexandria (Virginia): American Statistical Association. Available: http://www.amstat.org/profession/index.cfm?fuseaction=ethicalstatistics . Accessed 13 July 2005.
- 10. Altman DG (1991) Practical statistics in medical research. London: Chapman and Hall. 611 p.
- 11. Snedecor GW, Cochran WG (1980) Statistical methods, 7th ed. Ames (Iowa): Iowa State University Press. 507 p.
- 12. Iglewicz B, Hoaglin DC (1993) How to detect and handle outliers. Milwaukee (Wisconsion): ASQC Quality Press. 87 p.
- 14. Welsch RE (1982) Influence functions and regression diagnostics. Launer RL, Siegel AF, editors. New York: Academic Press. pp. 149–169. Modern data analysis.
- 15. Haykin S (1994) Neural networks: A comprehensive foundation. New York: Macmillan College Publishing. 696 p.
- 16. SAS Institute (2002) Enterprise miner, release 4.1 [computer program]. Cary (North Carolina): SAS Institute.
- 17. Myers RH (1990) Classical and modern regression with applications, 2nd ed. Boston: PWS-KENT. 488 p.
- 20. Centers for Disease Control and Prevention (2002) Epi Info, revision 1st ed. [computer program]. Washington (D. C.): Centers for Disease Control and Prevention. Available: http://www.cdc.gov/epiinfo . Accessed 14 July 2005.
- 21. Lauritsen JM, Bruus M, Myatt MA (2001) EpiData, version 2 [computer program]. Odense (Denmark): Epidata Association. Available: http://www.epidata.dk . Accessed 14 July 2005.
- 23. Winkler WE (1998) Problems with inliers. Washington (D. C.): Census Bureau. Research Reports Series RR98/05. Available: http://www.census.gov/srd/papers/pdf/rr9805.pdf . Accessed 14 July 2005.
- 25. Gardner MJ, Altman DG (1994) Statistics with confidence. London: BMJ. 140 p.
- 27. Allison PD (2001) Missing data. Thousand Oaks (California): Sage Publications. 93 p.
- 29. Schafer JL (1997) Analysis of incomplete multivariate data. London: Chapman and Hall. 448 p.
- 30. South Africans Medical Research Council (2000) Guidelines for good practice in the conduct of clinical trials in human participants in South Africa. Pretoria: Department of Health. 77 p.
ThoughtSpot Analytics
Deliver insights 10x faster for your employees
AI-Powered Analytics for your modern data stack
Create insights in seconds with AI-powered search
Create insights in seconds using natural language search
Live-query your data cloud or lake in a few clicks
Build search data models in ThoughtSpot
Govern & Secure
Balance self-service with enterprise-scale control
Keep a finger on the pulse of your business with Liveboards
Augmented Analytics
Surface actionable insights fast with AI
- Operationalize
Schedule and sync cloud data directly to business apps
Know what's happening and why, wherever you are
Spreadsheets
Search to create visualizations from data in Microsoft Excel and Google Sheets
New Features
Stay up to date with the latest product news and releases
ThoughtSpot Embedded
Drive higher app engagement with embedded analytics
Embed engaging self-service analytics experiences into any app
Embed analytics with a few lines of code
Get a jumpstart to building ThoughtSpot apps and API services
Developer Playground
Explore ThoughtSpot Embedded’s SDK and APIs
Get the latest new features and enhancements in ThoughtSpot Embedded
Generate more revenue with embedded analytics

Gartner 2024 Magic Quadrant™ for Analytics and BI Platforms

Interactive Product Tour
Experience the power of Search and Liveboards for yourself
- Business Leader
- Data Leader
- Product Leader
By Industry
- Financial Services
Retail & E-commerce
Manufacturing & Logistics
Healthcare & Life Sciences
Media & Communications
- Procurement
- Public Sector
By Department
- ServiceNow Analytics

Dashboards are dead: AI edition
Demo Videos
The Data Chief
Data Trends
- Documentation
Analyst Reports
White Papers
Case Studies
Solution Briefs
User Groups
- Professional Services

Meet the future of analytics in our live weekly demo sessions.
Support Center
- Atlas Marketplace
In The News
Press Releases
Technology Alliances
Channel Partners
System Integrators
All Partners

Experience AI Analytics yourself with our interactive product tour.
Data cleaning: what it is, examples, and how to keep your data clean in 7 steps.

As an industry, we rely on data to separate the signal from the noise, unearth insights, and make better decisions. Inconsistencies in data entry, incorrect or missing values, and extraneous information all muddy the waters, making it difficult to get accurate insights and eventually eroding trust, even for organization’s with mature business intelligence initiatives. As they say, garbage in, garbage out.
If your users do not trust the data, then it doesn't matter if you have empowered them to analyze the data themselves with self-service analytics tools. They simply won’t adopt them.
That’s why data cleaning is critical to getting the most value possible from the modern data stack .
Table of contents:
What is data cleaning?
- Why is data cleaning so important?
Top data cleaning benefits
Real-life examples of data cleaning, how to clean data, step 1: identify data discrepancies using data observability tools, step 2: remove data discrepancies, step 3: standardize data formats, step 4: consolidate data sets, step 5: check data integrity, step 6: store data securely, step 7: expose data to business experts, make quicker and better decisions from your data.
Data cleaning is the process of identifying and correcting errors and inconsistencies in data sets so that they can be used for analysis. It is a crucial step in data preprocessing and is essential for ensuring the quality and reliability of the data used for analysis or machine learning applications. Thorough data cleaning helps you get a clearer picture of what is happening within your business, deliver trustworthy analytics, and create efficient processes.
So, why is data cleaning so important?
In a word: accuracy. The more accurate your data set, the more accurate your insights will be. And as research from Harvard Business Review points out, when it comes to making business decisions, whether by executives or frontline decision makers, every insight matters. That's why data cleaning should be at the top of your list of priorities if you want to get the most out of your data. In this post, we will discuss the top five benefits of cleaning your data, real-life data cleaning examples, and seven steps to follow to clean your data properly.
Data cleaning is an important part of data management that can have a significant impact on data accuracy, usability, and analysis. Through data cleaning techniques such as data validation, data verification, data scrubbing, and data normalization, businesses can ensure the accuracy and integrity of their data. Data cleaning is an essential data management task that can provide many benefits to organizations including:
Improved data accuracy
By regularly cleaning data, especially as part of an automated data pipeline , it is possible to reduce the risk of errors and inaccuracies in data records. This data integrity is essential for data analysis and allows organizations to make data-driven decisions with greater confidence.
Increased data usability
Clean data can be trusted in a wider array of use cases by data professionals like analytics engineers , making data more accessible and valuable across different areas of the business and to different kinds of users. By cleaning data, organizations can ensure that data is in a consistent format and can be used for a variety of data-driven tasks.
Easier data analysis
Clean data provides the foundation for data analysis, making it easier to gain insights from data. It is important to ensure data records are accurate and up-to-date in order to deliver reliable data analytical results.
Ensure data governance
The right data governance program, where data is secure and only accessible by the right individuals is an essential component of any data strategy. With proper data cleaning, organizations can adhere strictly to data governance initiatives that protect privacy.
More efficient data storage
Data cleaning can help to reduce data storage costs by eliminating unnecessary data and reducing data duplication, whether you’re using a cloud data warehouse or a traditional on-prem solution. By consolidating data records, organizations can minimize data storage requirements and optimize the use of data resources.
Data cleaning is a crucial step in any data analysis process as it ensures that the data is accurate and reliable for further analysis. Here are three real-life data-cleaning examples to illustrate how you can use the process:
Empty or missing values
Oftentimes data sets can have missing or empty data points. To address this issue, data scientists will use data cleaning techniques to fill in the gaps with estimates that are appropriate for the data set. For example, if a data point is described as “location” and it is missing from the data set, data scientists can replace it with the average location data from the data set. Alternatively, organizations can find a data point from another data source to fill this gap.
In data sets, there could be data points that are far away from other data points in terms of value or behavior. This can skew the results of data analysis and lead to false results or poor decisions. That’s why understanding outliers and anomalies is very important for ensuring accuracy. To address this issue, data scientists can use data cleaning techniques to identify and remove outliers in data sets.
Data formatting
Data formatting includes changes such as converting data into a particular data type, changing the structure of the data set, or creating the right data model . Inconsistent data types and structures can lead to errors during data analysis, so data scientists should use data cleaning techniques to ensure data sets are formatted correctly. For instance, data scientists can convert categorical data into numeric data or combine multiple data sources into one data set.
Creating clean, reliable datasets that can be leveraged across the business is a critical piece of any effective data analytics strategy , and should be a key priority for data leaders. To effectively clean data, there are seven basic steps that should be followed:
At the initial phase, data analysts should use data observability tools such as Monte Carlo or Anomalo to look for any data quality issues, such as data that is duplicated, missing data points, data entries with incorrect values, or mismatched data types.
Once the data discrepancies have been identified and appropriately evaluated, data analysts can then go about removing them from the existing dataset. This may involve removing data entries or data points that are irrelevant, merging data sets together, and ensuring data accuracy.
After data discrepancies have been removed, standardizing data formats is essential in order to ensure consistency throughout the dataset. For example, one data set may contain dates formatted differently than another data set. Data analysts should ensure that all data is stored in the same format, such as YYYY/MM/DD or MM/DD/YYYY, across all data sets.
Then, different data sets can be consolidated into a single data set unless data privacy laws prevent them from doing so. Often, this requires breaking down silos between datasets and bringing them together. Many organizations rely on emerging data architectures, whether they’re using or considering a data lake , data warehouse , or data lakehouse , to do so. Consolidating data sets makes data analysis more efficient as it reduces data redundancy and streamlines the data processing process.
Data professionals should then check for data integrity by ensuring that all data is accurate, valid, and up-to-date before proceeding to data analysis or data visualization . This is done by running data integrity checks or data validation tests on the data.
Then, data professionals must store data securely in order to protect it from unauthorized access and data loss. This includes encrypting data at rest, using secure file transfer protocols for data transmissions, and regularly backing up data sets.
Finally, the last step is exposing data to business users. These domain experts have deep knowledge, and can quickly help identify data that’s inaccurate or out of date. This mutual partnership between data and business teams requires the right self-service business intelligence solution, so business users can focus on exploring data to find data cleanliness issues.
By following these seven data cleaning steps, data analysts can ensure data reliability and integrity while also reducing data redundancy. This in turn allows data scientists to make trustful insights from their data and improve the overall accuracy of data-driven decisions.
It’s crucial that you take the time to clean your data before turning it into insights. The benefits of data cleaning are numerous and can save you a lot of time and effort in the long run. This is especially true for organizations taking a modern approach to data cleaning, where business users are brought into the process earlier.
If you’re looking for an easier way to get insights into your clean data, or bring business users to your data, ThoughtSpot offers a 14-day free trial so you can see how to find valuable insights with self-service analytics yourself.
With ThoughtSpot, you can easily drill down into your data and get accurate insights instantly – without any headaches. So what are you waiting for? Sign up today !
ThoughtSpot is the AI-Powered Analytics company that lets everyone create personalized insights to drive decisions and take action.
- ThoughtSpot Sage
- Auto Analyze
- Govern & Secure
- New features
- Retail & E-commerce
- Manufacturing & Logistics
- Healthcare & Life Sciences
- Media & Communications
- Partner Directory
- Request Demo
(800) 508-7008
Stay in Touch
Get the latest from ThoughtSpot
How to Perform Data Cleaning in Survey Research + Top 7 Benefits

Ready to clean up your act? Then start with your data! Today, almost 95% of businesses suspect their customer and prospect data are inaccurate. And, it’s costing U.S. businesses more than $600 billion each year. So, it’s no wonder that companies are taking notice of the importance of data cleaning. Let’s look at how data cleaning works and its benefits.
Create your perfect survey, form, or poll now!
What is Data Cleaning?
Data cleaning (or data scrubbing) is the process of identifying and removing corrupt, inaccurate, or irrelevant information from raw data. Correcting or removing “dirty data” improves the reliability and value of response data for better decision-making. There are two types of data cleaning methods.
- Manual cleaning of data, done by hand, is quite time-consuming. It’s best performed on small data sets.
- Computer-based data cleaning ( a utomated data cleaning) is quicker and ideal for large data sets. It uses machine learning to carry out the data cleaning objectives.
Why is Data Cleaning Important in Survey Research?
While data cleaning may be expensive and time-consuming, using raw data can lead to many problems. Here are the top seven benefits of data cleaning.
1. Increasing Revenue
Many surveys are conducted to develop new marketing tactics. When a company has accurate data from its target audience, it can proceed with more confidence. This allows them to get better results and greater ROI on marketing and communications campaigns.
Clean data can also be segmented to focus on high-value prospects. These are the customers who are most likely to drive sales that companies want to focus on. Data scrubbing also helps businesses identify opportunities, such as a new product or service.
2. Improving Decision Making
Mistakes are bound to happen without clean data. The mistake could be huge, such as botching a new product release. Or, it could simply be embarrassing, such as being called out for bad data. Data cleaning is designed to reduce or eliminate inaccurate information that may mislead company decision-makers. Clean data provides more accurate analytics that can be used to make informed business decisions. This, in turn, contributes to the long-term success of the business.
3. Improving Productivity
A company’s contact database is one of its most valuable assets! However, have you ever stopped to think about how up-to-date it is? If it’s not current, your sales team may waste many hours per week contacting expired contacts or uninterested individuals.
Studies show that prospect and customer databases tend to double every 12-18 months. So, they can quickly become cluttered with inaccurate data. With accurate and updated information, employees will spend less time contacting expired contacts. This gives them more time to reach out to those who are truly interested in your products/services.
4. Boosting Your Reputation
It’s important to build and maintain a reputation with the public. This is especially important if you’re a company that regularly shares data with them. If you consistently provide clean data, they’ll come to trust you as a resource. However, just a few instances of inaccurate reporting can have them looking for a more reliable source.
One more consideration: With an inaccurate list, you’re bound to solicit people who aren’t interested in your company. As a result, they’ll perceive your calls and/or emails as spam, hurting the company’s integrity.
5. Maintaining Compliance
When it comes to people’s personal information, security is more important than ever. This is especially true with the introduction of GDPR compliance . By regularly cleansing your databases, you can keep an eye on customer contact permissions to be sure only opt-ins are solicited. This can help avoid the fines associated with breaching GDPR and other legislation.
6. Saving Money
Do you employ physical marketing strategies, such as direct mail coupons, newsletters, or magazines? Mailouts based on raw data can result in you reaching people that aren’t interested. You could also reach people who have moved or who have passed on. That’s a big waste of money and marketing materials!
7. Reducing Waste
Clean data reduces the amount of printing and distribution required for mailings because you’re only targeting legitimate, interested customers. Not only is this good for the business, but it’s also good for the environment! Heal the Planet reveals that junk mail adds 1 billion pounds of waste to landfills each year.
How to Perform Data Cleaning (7 Things To Look For)
The data cleaning process is all about spotting suspicious data and irregularities. Here’s a look at some of the most common things to look out for when cleaning up data on surveys.
1. Unanswered Questions
Respondents who only answer a portion of your questions can lead to survey bias by skewing the results. It could mean they weren’t qualified to take the survey so they left some questions blank. It could also indicate that they weren’t engaged in the survey and opted out early. It’s important to note that if a lot of respondents failed to complete the survey, it may have been due to bad survey design. That could mean poorly worded or irrelevant questions , broken survey logic, etc.
2. Unmet Target Criteria
Unqualified individuals can still sneak into a survey. Of course, if you’re surveying young women, for example, you don’t want the opinion of a middle-aged man influencing your findings! To remedy this, be sure to always ask screening questions and appropriate demographic questions to weed out undesirable respondents.
3. Speeders
These are people who speed through your survey, taking little time to read the questions (if they bother at all). This happens on required surveys people aren’t interested in, or they may rush through it to get a survey incentive . You can identify speedy survey takers by averaging out the response time for all participants and eliminating those that completed it in far less time.
4. Straightliners
Straightling is when participants choose the same answer over and over again. They may always choose “strongly agree,” for example (this is also a form of speeding). Of course, it’s possible that a participant does strongly agree with every statement. So, you can identify a straightliner by rephrasing a couple of questions with similar responses in different positions. You might also avoid matrix surveys, which easily allows someone to go down a column and click the same response. SurveyLegend’s matrix-type questions are viewed on individual scrolls , making someone much less likely to straightline responses.
5. Inconsistent Responders
Many surveys will ask what appear to be redundant questions, but this is done to catch speeders and straightliners due to inconsistency in their responses. For example, you may ask someone how often they watch the news, and then filter by those who said “a few times per week.” On another question, you could ask what their favorite news program is, and then filter responses by “I don’t watch the news.” If a respondent has contradictory answers like this, it’s clear they were either being dishonest or careless. Either way, you’ll likely want to remove them from your analysis.
5. Unrealistic Responders
Some surveys will include unrealistic responses to try to catch speeders and straightliners. For example, when asking how many hours per week someone uses the internet, they may include 170 hours as an option. Of course, there are only 168 hours in a week, making this impossible!
6. Outliers
Back to the example above. If someone says they use the internet 150 hours per week (which is possible, however unlikely), they are what’s known as an outlier. This does not reflect the internet usage of the general population, so it should be removed from the survey as not to skew results.
7. Nonsensical Responders
Does your survey have open-ended questions? If someone fills in the blank with gibberish, say a random word or just a series of keystrokes, they’re obviously not engaged or are speeding. The results should be removed from your survey analysis.
Additional Data Cleaning Tips
Here are a few more tips to consider when it comes to data cleaning.
Remove Irrelevant Values
You want your data analysis to be as simple as possible, so remove irrelevant data. For example, do you want to know the average education level of your employees? Then remove the email field if you won’t be following up.
Remove Duplicate Values
Duplicates can skew your data and waste your time. They could exist because you combined data from multiple resources, or perhaps the survey-taker hit “submit” twice and it went through. Either way, remove them for accuracy.
People make mistakes, and typos are very common. However, this can create havoc for some algorithms. So, if it’s clear what a respondent meant, you can fix the typo to make sure the response is counted.
Consider String Size
This is another form of a typo. A respondent (usually accidentally) doesn’t complete a string of digits. For example, they type 3360 for their zip code, perhaps because they simply didn’t hit the last key hard enough to register. If you have a good idea of your respondent’s location, you can fill in the string, or remove the response from the analysis.
Convert Data Types
Stored numbers as numerical data types for consistency. Stored a date as a date object, a timestamp as a number of seconds, and so on. Categorical values can also be converted into and from numbers for easier and more accurate analysis.
Data cleaning is a must for accurate and useful survey results. While it can be a time-consuming process, it has many benefits. SurveyLegend lets you quickly and easily create professional online surveys. You can also delete individual responses when data cleaning. Whether the response isn’t complete, doesn’t offer insight, or seems “suspicious,” our survey platform makes data cleaning less of a chore. You can also easily find and track the answers of each individual respondent. Just export your survey data in Google Drive or in Excel for further analysis and cleansing.
Do you practice good data hygiene? Any unique data cleaning methods you use that we’ve missed? Sound off in the comments!
Frequently Asked Questions (FAQs)
Data cleaning involves identifying and removing corrupt, inaccurate, or irrelevant information from raw data to improve the accuracy and value of response data.
Data cleaning helps companies make better marketing decisions. It also helps researchers present more accurate data when reporting on issues impacting the public.
Signs that your raw data may be inaccurate, or “dirty,” include unanswered questions, unmet criteria, and inconsistent or unrealistic answers. Types of respondents to watch out for are speeders (those that rush through the survey), straightliners (those who always choose the same answer), and outliers (those whose responses are very different from the mean).
Data cleaning methods include removing irrelevant data and duplicate values, fixing typos, checking string sizes (in regards to numbers), and converting data types.
Jasko Mahmutovic

Related Articles You Might Like

8 Types of Opt-Out Surveys + Legal Considerations
Have you ever received an unexpected survey from a company or organization? More than likely, you had an interaction with them, but to your knowledge, you didn’t agree to...

How To Use An Exit Intent Survey + Pros & Cons
“Hey, where you going?” In a nutshell, that’s the gist of an exit intent survey. These online surveys are designed to capture feedback from website visitors who are about...

7 Reasons To Use A Cancellation Survey & Questions To Ask
No company likes to see a customer leave. For one, it’s been drilled into all of us that it costs a lot more to acquire a new customer than...
Privacy Overview

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Interact J Med Res
- PMC10557005
Normal Workflow and Key Strategies for Data Cleaning Toward Real-World Data: Viewpoint
Manping guo.
1 Postdoctoral Research Station, China Academy of Chinese Medical Sciences, Beijing, China
2 Postdoctoral Works Station, Yabao Pharmaceutical Group Co, Ltd, Yuncheng, China
3 Xiyuan Hospital, China Academy of Chinese Medical Sciences, Beijing, China
Yiming Wang
Qiaoning yang.
4 First Affiliated Hospital, Henan University of Traditional Chinese Medicine, Zhenzhou, China
5 Beijing Xinshi Yuanzhi Technology Consulting Co, Ltd, Beijing, China
Associated Data
Supplementary figures 1-9.
With the rapid development of science, technology, and engineering, large amounts of data have been generated in many fields in the past 20 years. In the process of medical research, data are constantly generated, and large amounts of real-world data form a “data disaster.” Effective data analysis and mining are based on data availability and high data quality. The premise of high data quality is the need to clean the data. Data cleaning is the process of detecting and correcting “dirty data,” which is the basis of data analysis and management. Moreover, data cleaning is a common technology for improving data quality. However, the current literature on real-world research provides little guidance on how to efficiently and ethically set up and perform data cleaning. To address this issue, we proposed a data cleaning framework for real-world research, focusing on the 3 most common types of dirty data (duplicate, missing, and outlier data), and a normal workflow for data cleaning to serve as a reference for the application of such technologies in future studies. We also provided relevant suggestions for common problems in data cleaning.
Introduction
Randomized controlled trials (RCTs) are considered to yield the highest-level evidence in the practice of evidence-based medicine, representing the “gold standard” for evaluating the safety and efficacy of drugs [ 1 ]. However, the extrapolation of RCT results to real-world situations is limited because of strict screening conditions, single-intervention measures, and limited sample sizes [ 2 ]. To compensate for the shortcomings of RCTs, Kaplan et al [ 3 ] first proposed the concept of real-world research (RWS) in 1993. RWS focuses on using high-quality, real-world data to generate reliable evidence regarding the effects of medical interventions in a real-world environment to complement the evidence generated from traditional RCTs.
The role of massive real-world data in academic and business environments has become increasingly significant [ 4 ]. To better understand the value of these data, data mining and analyses are required [ 5 ]. However, real-world data from medical practice are usually generated without the strict process controls applied in clinical trials. For example, when data are collected from multiple sources, such as different hospitals or hospital systems, the rules for integration may not be identical, leading to quality issues such as duplicate, missing, and outlier data. These “dirty data” are ubiquitous in RWS. Among them, the large amount of storage space required for duplicate data affects the efficiency of the database, and the inappropriate processing of missing data can result in the loss of a considerable amount of potentially useful information. Furthermore, inconsistent or incorrect outlier data can seriously affect the results of data analyses and key calculations, which may even provide incorrect directions for subsequent academic research, resulting in a loss of time, effort, and funding [ 6 ].
The China Center for Drug Evaluation issued a document titled “Guidance on Real-World Data for Generating Real-World Evidence (Trial)” [ 7 ] (referred to as “the guidance” in this study) in 2021, which emphasizes that “not all real-world data can produce real-world evidence when analyzed.” The role of data cleaning is to process dirty data to regenerate real-world data that can be used to form real-world evidence. A standardized data cleaning process is critical to improving data quality. The guidance proposes essential requirements for real-world data governance; however, it does not outline the specific processes and approaches for data cleaning in detail. In this study, we outlined the current data-cleaning approaches for RWS and proposed a normal workflow for data cleaning to serve as a reference for applying such technologies in future studies.
Impact of Data Cleaning on Data Quality
Data cleaning is the process of identifying and solving problems, which is crucial for the management of data quality [ 8 ]. The lack of an effective data cleaning process may result in a “garbage in and garbage out” scenario [ 8 ], adversely affecting the subsequent data analysis. In contrast, an effective data-cleaning process can transform dirty data into clean, reliable data that reflect real-world situations, providing researchers with more valuable information [ 9 ]. Therefore, data cleaning plays a decisive role in improving data quality.
Categorizing Issues With Data Quality
Data quality is the degree to which the accuracy, completeness, consistency, and timeliness of the data satisfy the expected needs of specific users. Issues with data quality can be categorized as either pattern-layer or instance-layer, depending on the level at which the issues are observed. Similarly, issues can be categorized as single-source or multi-source, depending on the data source. Therefore, issues with data quality are typically divided into 4 categories: single-source pattern-layer issues, multi-source pattern-layer issues, single-source instance-layer issues, and multi-source instance-layer issues ( Figure 1 ) [ 10 ].

Classification of data quality issues.
Causes of Data Quality Issues
Pattern-layer issues originate from deficiencies in the system design. For single data sources, pattern-layer issues include a lack of integrity constraints and low-end architectural design. For multiple data sources, pattern-layer issues can also include structural and naming conflicts among the sources. Pattern-layer issues are not the main focus of data governance for RWS; however, many issues in the instance layer are caused by unresolved errors in the pattern layer.
At the instance layer, data issues mainly arise from human errors, which is a key focus of RWS on data governance. Common causes of data record exceptions at the single-source instance layer include data input errors, similar or duplicate records, and missing values. Input errors occur mostly during the process of case recording and are common in data sources that rely heavily on manual input, such as hospital information system data and individual health monitoring data from mobile devices. Similar or duplicate records may arise from operational errors during manual data entry. However, they may also arise when 2 cases with different levels of completeness are stored for the same patient during the same time period. This latter scenario is common when exporting data for different time periods, such as from January to June and June to December successively. Missing values may arise from technical errors in recording or deliberate concealment on the part of the patient (eg, refusal to provide relevant information). Alternatively, missing values can be caused by failures in data storage or error clearance resulting from equipment issues. In some cases, highly sensitive data may also be difficult to obtain (eg, medical insurance payment data).
In addition to all the problems that can arise at the instance layer for single sources, unique multisource issues in the instance layer include inconsistent data time and aggregation. Among them, similar or duplicate records resulting from identifying the same content as different objects (ie, use of different expressions) are the main problems.
Data cleaning can effectively address issues at the instance layer. To improve data quality, this step should be integrated into the processing pattern layer.
Data Cleaning
Definition of data cleaning.
Data cleaning is a series of processes that streamline the database to remove duplicate records and convert the remaining information into standard-compliant data. More specifically, data cleaning involves the preprocessing of the extracted raw data, which includes elements such as the removal of duplicate or redundant data, logical verification of variable values, treatment of outliers, and processing of missing data. Thus, any operation performed to improve data quality can be classified as data cleaning. Data cleaning also encompasses all processes used to detect and repair irregularities in data collection and improve data quality. In the process of data cleaning, the corresponding cleaning rules can be formulated, and the data-cleaning framework and cleaning algorithms can be used to make the data-cleaning process easier and more efficient.
The guidance suggests that real-world data can be obtained prospectively and retrospectively, requiring data management and governance, respectively. Data cleaning is an element of data governance and is not required in the data management process. Therefore, data cleaning is generally suitable for real-world data collected retrospectively. The guidance divides data cleaning in RWS into the processing of duplicate, outlier, and missing data.
Basic Process for Data Cleaning
Relevant technical means, such as data mining, mathematical statistics, or predefined cleaning rules, are used to convert dirty data into data that meet quality requirements ( Figure 2 ). Data cleaning is generally divided into 4 types: manual cleaning, machine cleaning, synchronous human-machine combined cleaning, and asynchronous human-machine combined cleaning [ 11 ]. The unprocessed source data are first collected directly from the database (ie, dirty data), following which the corresponding data cleaning rules are applied. The process can be streamlined using an appropriate data-cleaning framework and cleaning algorithms. Fully manual, fully automated, or combined strategies can be used until quality requirements are met.

Basic process of data cleaning.
Despite its high accuracy, manual cleaning is only suitable for smaller data sets, given its time-consuming nature. In contrast, machine cleaning is more suitable for processing larger data sets since the process is completely automated. However, the cleaning plan and program must still be developed in advance, making later-stage maintenance difficult. In the synchronous human-machine strategy, problems that cannot be handled by the machine are manually addressed through an appropriate interface. This method is advantageous because it reduces the workload of manual cleaning while reducing the difficulty of designing the machine cleaning strategy. In principle, the asynchronous human–machine strategy is similar to its synchronous counterpart; however, when problems that cannot be handled by the machine are encountered, the issues are not addressed in real time. Instead, a problem report is generated, and cleaning proceeds to the next step. Thus, manual processing occurs after cleaning and is the method currently used by most cleaning software.
Normal Workflow for Data Cleaning
Depending on the task requirements, the data-cleaning workflow can be performed differently. The general data-cleaning process can be divided into 5 components ( Figure 3 ).

Normal workflow for data cleaning.
Step 1: Back Up and Prepare the Raw Data for Cleaning
Data collected from different sources must be combined before further data governance and analysis can be performed. Therefore, it is necessary to unify the data types, formats, and key variable names in different databases before data cleaning. In addition, the original data must be backed up and archived before cleaning to prevent damage or loss of data during the cleaning process. This step is also crucial in cases requiring cleaning policy changes.
Step 2: Review the Data to Formulate Cleaning Rules
Appropriate cleaning methods (manual, machine, or combined) should be selected according to the size of the data set. After analyzing and summarizing the characteristics of the data source, the proposed cleaning algorithm and corresponding cleaning rules are formulated. Cleaning rules are divided into 3 categories: processing of missing, duplicate, and outlier data.
Step 3: Implement the Cleaning Rules
The execution of cleaning rules is the core step in the data cleaning process, and data processing can be performed in the following order: duplicate, missing, and outlier data ( Figure 4 ). However, given the differences in professional fields and situational factors, adopting a common, unified standard for data cleaning is difficult. In addition, there are many types of data quality problems and complex situations, making a generalization based on categories difficult. Therefore, the corresponding cleaning rules must be formulated on a situational basis.

Execution of data cleaning rules: an example sequence.
Step 4: Verify and Evaluate the Quality of the Cleaned Data
Following data cleaning, the quality of the data should be assessed according to the cleaning report generated, and problems that could not be addressed by the machine must be handled manually. Evaluating the data quality will also enable the optimization of the program and algorithm to ensure that future processes yield data of sufficient quality. After redesigning the program based on these observations, the cleaning step should be repeated as needed until the requirements for analysis have been met.
Step 5: Warehouse After Data Cleaning
Following data cleaning, a new target database should be established for the cleaned data. While this aids in archiving and preservation, appropriate warehousing of the data can prevent the need for repeated cleaning work in the future.
Summary of Data Cleaning Methods for the Instance Layer
This section describes the methodology of the data cleaning methods, including the data sets, the 3 types of dirty data, and the corresponding data cleaning methods.
In this study, we used a data set from a retrospective heart failure cohort in the Research Resource for Complex Physiologic Signals (PhysioNet) database [ 12 ]. This heart failure cohort retrospectively collected electronic medical records of 2008 hospitalized patients with heart failure from the Fourth People’s Hospital of Zigong City, Sichuan Province, China, from December 2016 to June 2019. The identification of hospitalized patients with heart failure was based on the International Classification of Diseases-9 code. Furthermore, the diagnostic criteria followed the 2016 European Society of Cardiology Heart Failure Diagnosis and Treatment Guidelines. The partial information contained in the data set is presented in Figure S1 in Multimedia Appendix 1 , with 167 variables (n=167), including 2008 records (N=2008), and saved as a CSV file.
To provide a more intuitive demonstration of the results in the following examples, we added 30 records as “duplicate data” in the heart failure data set and manually adjusted the “systolic blood pressure” values in 11 records as “abnormal data.” According to the admission way (column E), patients with heart failure were divided into 2 groups: the emergency and nonemergency groups, and the urea values (column BO) were analyzed and compared between these 2 groups. There are “missing data” in the urea values of the 2 groups (Figure S2 in Multimedia Appendix 1 ):
Processing of Duplicate Data
Methods for detecting duplicate data can be divided into record-based and field-based methods. Record-based duplicate detection algorithms include the N-grams, sorted-neighborhood method (SNM), clustering, and most probable number (MPN) algorithms [ 13 - 15 ]. Field-based repeat detection algorithms include the cosine similarity function [ 16 ] and Levenshtein distance algorithms [ 17 ]. The main processes involved in duplicate data cleaning are as follows:
Step 1: Analyze the attribute segments of the source database, limit the key search values of the attributes (eg, name, patient ID, and date of treatment), and sort the data in the source database from the bottom to the top or top to bottom according to the key search values.
Step 2: Scan all data records according to the order of arrangement, compare the adjacent data, and calculate the similarity of the matching data records. The duplicate data retrieval code for the sample data set is presented in Figure S3 in Multimedia Appendix 1 .
Step 3: Deduplicate or merge the duplicate data. When the similarity value of adjacent data is higher than the threshold defined by the system, the continuous data records are identified as similar or duplicate data. The duplicate data retrieval results of the sample data set are presented in Figure S4 in Multimedia Appendix 1 . These data should be deduplicated or merged. Similarly, when the similarity value is below the threshold defined by the system, scanning should be continued, and steps 2 and 3 should be repeated as necessary.
Step 4: After testing all data records, generate a report and archive the data before and after it. The workflow for cleaning duplicate data is shown in Figure 5 .

Cleaning workflow for duplicate data.
Processing of Missing Data
While deletion is initially considered for missing values, this only applies if the data set is large, and the proportion of missing data is not large. If the amount of data is not sufficiently large, directly deleting missing values will lead to data loss, resulting in the deletion of many useful statistics. Feasible methods for addressing missing values include using missing-value imputation technology for repair. Commonly used methods for imputation include mean imputation, mode imputation, minimum imputation, regression imputation, and maximum likelihood estimation [ 18 - 21 ], and using a Bayesian or decision tree classifier [ 22 ] to model the missing value imputation as a classification problem. The main processes involved in cleaning missing data are as follows:
Step 1: Perform parameter estimation for missing values in the source data and select the deletion method or imputation method according to the proportion of missing values. The missing data retrieval code for the sample data set is presented in Figure S5 in Multimedia Appendix 1 .
Step 2: Fill in the missing data according to the data-filling algorithm. The missing data retrieval and interpolation results of the sample data set are presented in Figure S6 in Multimedia Appendix 1 . For the convenience of demonstration, the mean interpolation method was chosen, and specific problems should be analyzed in practical application.
Step 3: Output and archive the complete data. The workflow for cleaning missing data is shown in Figure 6 .

Cleaning workflow for missing data.
Processing of Outlier Data
An outlier is a value that does not conform to attribute semantics. There are 2 methods for handling outlier data: deletion and replacement. However, the appropriate methods should be selected based on the nature of the data. If the nature of the outlier data is unsuitable for replacement, such as age data, outlier analysis can be used to detect and delete outliers. Outlier detection algorithms mainly include cluster-based, statistical model-based, density-based, and proximity-based algorithms [ 23 ]. If the nature of the abnormal data is suitable for replacement, the regression method or mean smoothing method can be used to replace the abnormal values. The regression method is applicable to data conforming to a linear trend, while the mean smoothing method is more effective in cleaning data with sinusoidal time-series characteristics [ 24 ]. The main processes involved in cleaning outlier data are as follows:
Step 1: Convert the source data into the data format required for detection and conduct data preprocessing. The exception data retrieval code for the sample data set is presented in Figure S7 in Multimedia Appendix 1 .
Step 2: Perform outlier detection on the data after preprocessing. The abnormal data retrieval results of the sample data set are presented in Figures S8 and S9 in Multimedia Appendix 1 . If the nature of the outlier data is not suitable for replacement, delete the outliers. If the nature of the outlier data is suitable for replacement, use the regression or mean smoothing method to replace the outliers. Often, the repaired data can lead to new data exceptions, making it necessary to repeat steps 1 and 2 until the requirements are met.
Step 3: Restore the repaired data to its original format and perform archiving. The workflow for cleaning outlier data is shown in Figure 7 .

Cleaning workflow for outlier data.
Data Cleaning Tools
Oni et al [ 25 ] reported 4 tools commonly used in the data cleaning industry: Data Wrangler, OpenRefine, Python, and R. They explained that these tools are the most popular tools for data cleaning in RWS. OpenRefine, R, and Python are all open-source tools, making them easy to access and use. Data Wrangler is a commercial tool, but there is a community version that efficiently cleans up data. The characteristics of these tools are described below and presented in Table 1 .
Comparison of Data Wrangler, Python, R, and OpenRefine.
| Criteria | Data Wrangler | Python | R | OpenRefine |
| Import format | Excel, CSV, and text | All | All | Excel, CSV, TSV , XML, JSON, and RDF |
| Factors affecting the performance time | Data size and user choice | User programming skill level | User programming skill level | Data size and data format |
| Output format | CSV, JSON, and TDE | Any format | Any format | Excel, TSV, CSV, and HTML table |
| Skill level | Basic level | Advanced level | Advanced level | Basic or intermediate level |
| Running platform | Windows and Mac | All | All | All |
| Accuracy | Depends on the specific data quality issues (eg, missing values) | Depends on the user’s programming skill level | Depends on the user’s programming skill level | Depends on the specific data quality issues (eg, missing values) |
| Possibility to embedded | No | Yes | Yes | No, but code is available |
| Data set processing scale | Big data | Big data | Big data | Up to 5000 records |
| Graphic user interface | Yes | No | No | Yes |
a TSV: tab separated value.
b RDF: resource description framework.
c TDE: tableau data extract.
Data Wrangler
Data Wrangler is a web-based data cleaning and reorganization project developed by Stanford University [ 26 ]. It is a web-based data cleaning tool, mainly used to remove invalid data and organize data into user-required formats. Several data collations can be done in Data Wrangler with a simple click. It also lists the history of data modifications, making it extremely convenient for users to view past modifications and undo a modification operation. Data Wrangler can process data in 2 ways: users can either paste the data into its web interface or use the web interface to export any data operations to Python code and process them.
Advantages of Data Wrangler are that it has column and grid views, uses natural language to describe transformations, supports data visualization and every step of data cleaning, and supports large-scale editing. Disadvantages are that the free version of Data Wrangler provides only limited functionality and consumes a large amount of memory.
Python is a concise, easy-to-read, and extensible data-cleaning tool [ 27 ]. Currently, Numpy and PANDAS (Python Data Analysis Library) are the most used mainstream modules in Python for data cleaning. The PANDAS module is mainly used for data analysis, of which data cleaning is a part. The Numpy module has a powerful N-dimensional array object, and vectorization operations make data processing efficient and helpful in cleaning large data sets.
Advantages of Python are that it is easy to embed into other tools and applications, and users can customize solutions based on their needs. Disadvantages are that it requires users to have advanced programming skills, learn how to use many modules in Python, and understand the required steps during the cleaning process in advance, making it difficult to implement.
R is the language and operating environment used for statistical calculations, data analysis, and graphics [ 28 ]. R is a free, open-source software belonging to the GNU’s Not Unix (GNU) system. It can provide some integrated statistical tools. More importantly, it can provide various mathematical and statistical calculation functions, allowing users to flexibly analyze data and create new statistical calculation methods that meet their needs. R has a set of tools that can effectively and comprehensively clean data. The R environment can read data in multiple formats and process these files. R provides sufficient visualization tools. During the cleaning process, visualization of data at each stage is useful.
Advantages of R are that it supports the visualization of data and each step of data cleaning, making it more suitable for analyzing statistical data. Disadvantages of R are that it is not a good choice for projects outside data science. Users must understand the required steps during the cleaning process in advance, making it difficult to implement.
OpenRefine is a web-based ,independent, open-source application with various functions such as data portrait, cleaning, and conversion [ 29 ]. It can perform visual manipulations on data. It is similar to traditional Microsoft Excel software. However, it works like a database, as it does not deal with individual cells but rather with columns and fields. OpenRefine, formerly known as Google Refine, is a tool for cleaning, reshaping, and editing bulk, unstructured, and cluttered data. OpenRefine is a desktop application that opens as a local web server in a browser. Since it is an open-source project, its code can be reused in other projects. OpenRefine performs cleanup tasks by filtering and faceting, and then converts the data into a more structured format.
Advantages of OpenRefine are that it is a desktop application that does not require networking, making data sets more difficult to tamper with and relatively secure. It can be easily operated and has powerful functions for converting data. Users can use its facet function to filter data into subsets. Disadvantages include a limit of 5000 records, making OpenRefine not suitable for processing large data sets. It assumes that data is organized in a tabular format with limited operations and an unfriendly user interface. In addition, Google has removed support for the tool.
Documentation and Reporting
The Guidelines for Real-World Evidence to Support Drug Research and Development and Review (Trial) of the National Medical Products Administration of China (No 1 of 2020) stipulated that “transparency and reproducibility of evidence” should be achieved in the process of translating real-world data into real-world evidence, noting that proper documentation retention is the basis for ensuring transparency and reproducibility. We recommend that the data cleaning plan be stipulated in the RWS data governance plan, which should include personnel requirements, previous expectations for screening suspicious data, diagnostic procedures for identifying errors in the source data, cleaning tools, and decision rules to be applied in the cleaning phase.
Additionally, appropriate documentation should be provided at each of the following points: (1) precleaning (the raw data stage); (2) cleaning operation (during this stage, documentation should include differential markers of suspicious feature types, diagnostic information related to the type of dirty data, application algorithms and operational steps for data editing, and corresponding cleaning reports generated after cleaning is complete; simultaneously, the modification date must be marked for each operation, and the information of the relevant personnel involved in the modification must be saved); (3) the retention stage (after cleaning the data).
Recommendations for Data Cleaning
Most research projects do not formulate data-cleaning plans in advance. Analyses performed without complete cleaning of the dirty data will lead to biased results, and identifying the causes of any deviations from scratch will further delay the progress of the work. As the diversity of data sources increases the difficulty and workload of data cleaning, we recommend the following strategy.
First, formulate the cleaning plan in advance. As mentioned above, the results of statistical analyses are closely related to the cleanliness of the data. Data cleaning plans should be formulated in advance to ensure sufficient time and technical guidance for data cleaning.
Second, cultivate medical and computer talent. While analyzing real-world data, many medical researchers find that they do not understand computer programming. Conversely, many computer programmers do not have much medical expertise, resulting in poor communication between the two sides and affecting the development of data-cleaning strategies. Therefore, it is necessary to cultivate a group with compound talents who understand both medical statistics and computer applications.
Third, strengthen the computer skills training required for data cleaning. Hospitals and data companies should work together to organize and implement skills training for data cleaning in a timely manner. In addition, medical researchers and computer programmers should participate simultaneously to acquire professional knowledge from each other. Machine-based and manual methods can be selected to improve work efficiency when adopting combined human-machine cleaning strategies.
Fourth, establish a unified data governance and management platform. Researchers should fully use modern technical means to realize the collection, review, governance, and management of RWS data. Moreover, project researchers should perform unified management and maintenance of platform data.
Conclusions
Real-world data are large-scale with low value density. The data source yields dirty data, plagued by issues such as duplication, missing values, and outliers owing to various reasons. Analyses based on such data can severely reduce the efficiency of data use and negatively affect the quality of decision-making. Data cleaning technology can improve data quality and provides more accurate and realistic target data than the source data, which can then be used to support data consumers in making appropriate decisions. The data cleaning principles and workflows discussed in this study may aid in developing standardized methods for data cleaning in RWS.
Acknowledgments
The authors would like to acknowledge support from the foundation of the Science and Technology Innovation Project of the Chinese Academy of Traditional Chinese Medicine (Research on Key Technologies for Clinical Evaluation of New Chinese Medicines under the Three Combination Evaluation Evidence System), with the subject number CI2021A04701.
Abbreviations
| GNU | GNU’s Not Unix |
| MPN | most probable number |
| PANDAS | Python Data Analysis Library |
| RCT | randomized controlled trial |
| RDF | resource description framework |
| RWS | real-world research |
| SNM | sorted-neighborhood method |
| TDE | tableau data extract |
| TSV | tab separated value |
Multimedia Appendix 1
Authors' Contributions: RG and QL put forward the writing direction of this paper, MG was responsible for the idea and writing the first draft of this paper, and other authors participated in the discussion during the preparation of the paper. MZ, YC, and XJ were responsible for demonstrating the practical part of data cleaning. All authors contributed to the paper and approved the submitted version.
Conflicts of Interest: None declared.
- Advertise with Us
- Cryptocurrencies
Best Data Cleaning Tools for Analysts

Data cleaning is a critical step in the data analysis, ensuring that data is accurate, consistent, and ready for analysis. For analysts, having access to reliable data cleaning tools can significantly streamline the data preparation process, allowing them to focus on deriving insights rather than fixing errors. Here’s a roundup of the best data-cleaning tools that every analyst should consider in 2024.
1. OpenRefine
OpenRefine (formerly known as Google Refine) is a powerful open-source tool designed specifically for cleaning and transforming data. It supports a wide range of data formats and is particularly useful for dealing with messy data.
Key Features
Data exploration and cleaning capabilities
Faceted browsing to filter data easily
Supports data transformations using a robust expression language
Handles large datasets efficiently
Why It’s Great for Analysts
OpenRefine’s intuitive interface makes it easy for analysts to perform complex data-cleaning tasks without extensive coding knowledge.
Its powerful clustering and transformation functions can detect inconsistencies and standardize data quickly.
2. Trifacta Wrangler
Trifacta Wrangler is a popular tool among data analysts for data wrangling and preparation. It uses machine learning to suggest data transformations, making the data-cleaning process more efficient.
Smart suggestions for data transformations
Visual interface for intuitive data manipulation
Supports a wide range of data formats and sources
Real-time collaboration capabilities
Trifacta Wrangler’s smart suggestion feature speeds up the data cleaning process, allowing analysts to focus on analyzing data rather than preparing it.
Its visual interface simplifies the process of understanding and manipulating complex datasets.
3. Alteryx Designer
Alteryx Designer is a comprehensive data preparation tool that enables analysts to clean, blend, and transform data from multiple sources. It offers a drag-and-drop interface, making it accessible to users without advanced coding skills .
Drag-and-drop interface for data preparation
Extensive library of tools for data blending and transformation
Supports advanced analytics and predictive modeling
Integration with various data sources and platforms
Alteryx Designer’s user-friendly interface and robust capabilities make it ideal for analysts looking to perform complex data preparation tasks quickly.
The platform’s integration with other data sources allows for seamless data workflows, from data cleaning to advanced analytics.
4. Talend Data Preparation
Talend Data Preparation is a data cleaning tool that integrates seamlessly with Talend’s broader data integration platform. It’s designed to make the data preparation process faster and more efficient with its self-service data preparation capabilities.
Self-service data preparation
Data cleansing, normalization, and transformation
Integration with Talend’s data integration platform
Collaboration features for team-based data preparation
Talend Data Preparation allows analysts to easily clean and prepare data without needing IT support, empowering them to work more independently.
Its seamless integration with Talend’s other tools makes it a powerful choice for organizations already using Talend for data integration.
Dataiku is a data science platform that provides tools for data preparation, machine learning , and AI. Its data preparation features are particularly strong, offering a range of tools for data cleaning and transformation.
Visual interface for data preparation
Advanced cleaning functions, including deduplication and normalization
Collaboration and versioning features for team-based projects
Dataiku’s intuitive interface and comprehensive data preparation capabilities make it a versatile tool for analysts.
The platform’s collaboration features facilitate teamwork, allowing multiple analysts to work on data preparation simultaneously.
6. Pandas (Python Library)
Pandas is a powerful open-source data manipulation and analysis library for Python. While not a standalone tool, it is widely used by data analysts for data cleaning and preparation tasks.
Advanced data manipulation capabilities
Data cleaning functions, such as handling missing values and duplicates
Integration with other Python libraries for data analysis and visualization
Supports data from various formats, including CSV, Excel, and SQL databases
Pandas is highly flexible and powerful, allowing analysts to perform a wide range of data cleaning and manipulation tasks.
Its integration with other Python libraries makes it a versatile choice for analysts looking to perform end-to-end data analysis within the Python ecosystem.
7. TIBCO Clarity
TIBCO Clarity is a cloud-based data preparation tool that provides comprehensive data cleaning and transformation capabilities. It is designed to handle large datasets and support team-based data preparation.
Data profiling and cleansing tools
Support for large datasets and multiple data sources
Collaboration features for team-based projects
Integration with TIBCO’s broader data analytics platform
TIBCO Clarity’s powerful data profiling and cleansing tools make it a strong choice for analysts working with large and complex datasets.
The tool’s cloud-based nature allows for easy collaboration and scalability.
8. Tableau Prep
Tableau Prep is part of the Tableau suite of products, designed to help users clean and prepare data for visualization and analysis. It offers a visual interface for data preparation, making it accessible to non-technical users.
Integration with Tableau for seamless data visualization
Data cleaning and transformation tools
Real-time data updates and collaboration features
Tableau Prep’s visual interface simplifies the data preparation process, making it easy for analysts to see their data changes in real time.
The tool’s integration with Tableau allows for seamless transitions from data preparation to data visualization and analysis.
Data cleaning is an essential part of the data analysis process, and choosing the right tool can significantly enhance efficiency and accuracy. From open-source solutions like OpenRefine to advanced platforms like Alteryx Designer and Trifacta Wrangler, there are tools available to suit various needs and skill levels. Whether you're a seasoned data analyst or just starting, these data cleaning tools provide the functionality and ease of use needed to handle messy data and ensure high-quality outputs. By mastering these tools, analysts can save time on data preparation and focus more on deriving valuable insights.
Related Stories

An official website of the United States government
Here’s how you know
Official websites use .gov A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS A lock ( Lock A locked padlock ) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Data Catalog
- U.S. Environmental...
- U.S. EPA Office of...
SARS-CoV-2 Surface Cleaning Dataset
Cleaning efficacy study, for surfaces contaminated with SARS-Co-2.
This dataset is associated with the following publication: Nelson, S., R. Hardison, R. Limmer, J. Marx, B.M. Taylor, R. James, M. Stewart, S. Lee, W. Calfee, S. Ryan, and M. Howard. Efficacy of Detergent-Based Cleaning and Wiping against SARS-CoV-2 on High Touch Surfaces. Letters in Applied Microbiology. Blackwell Publishing, Malden, MA, USA, 76(3): ovad033, (2023).
Access & Use Information
Downloads & resources.
Task%204B%20SARS%20overall%20Data.xlsx
| Metadata Created Date | August 31, 2024 |
|---|---|
| Metadata Updated Date | August 31, 2024 |
Metadata Source
Download Metadata
Harvested from EPA ScienceHub
Other Data Resources
View this on Geoplatform
- antimicrobial
- surface-cleaning-agents
Additional Metadata
| Resource Type | Dataset |
|---|---|
| Metadata Created Date | August 31, 2024 |
| Metadata Updated Date | August 31, 2024 |
| Publisher | U.S. EPA Office of Research and Development (ORD) |
| Maintainer | |
| Identifier | https://doi.org/10.23719/1527855 |
| Data Last Modified | 2022-08-15 |
| Public Access Level | public |
| Bureau Code | 020:00 |
| Schema Version | https://project-open-data.cio.gov/v1.1/schema |
| Harvest Object Id | d56761c4-7611-4f03-9099-050e6a4b8ca9 |
| Harvest Source Id | 04b59eaf-ae53-4066-93db-80f2ed0df446 |
| Harvest Source Title | EPA ScienceHub |
| License | https://pasteur.epa.gov/license/sciencehub-license.html |
| Program Code | 020:000 |
| Publisher Hierarchy | U.S. Government > U.S. Environmental Protection Agency > U.S. EPA Office of Research and Development (ORD) |
| Related Documents | https://doi.org/10.1093/lambio/ovad033 |
| Source Datajson Identifier | True |
| Source Hash | 761e8320d13337d3bb738c2ca6f1367b5195e5f9eb2aabf90cfc980fca6df7b8 |
| Source Schema Version | 1.1 |
Didn't find what you're looking for? Suggest a dataset here .
We've detected unusual activity from your computer network
To continue, please click the box below to let us know you're not a robot.
Why did this happen?
Please make sure your browser supports JavaScript and cookies and that you are not blocking them from loading. For more information you can review our Terms of Service and Cookie Policy .
For inquiries related to this message please contact our support team and provide the reference ID below.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 09 September 2024
A study on the impact of ultrasonic-stimulated clean fracturing fluid on the pore structure of medium to high rank coal
- Zuo Shaojie 1 , 2 ,
- Xu Zhiyuan 1 ,
- Zhou Dongping 3 ,
- Ma Zhenqian 1 ,
- Liu Chengwei 4 &
- Zhao Fuping 5
Scientific Reports volume 14 , Article number: 21026 ( 2024 ) Cite this article
Metrics details
- Environmental impact
- Natural gas
The pore structure of coal plays a key role in the effectiveness of gas extraction. Conventional hydraulic fracturing techniques have limited success in modifying the pore structure using clean fracturing fluid (CFF), and the stimulating effects of ultrasonic can enhance the effectiveness of CFF in modifying coal pore structures. To research the effects of ultrasonic stimulation on the pore structure of medium to high-rank coal when using CFF, this study employed mercury intrusion porosimetry (MIP) and low-temperature nitrogen adsorption (LT-N 2 A) methods to analyze the changes in pore structures after cooperative modification. The results indicate that the pore volume and surface area of medium to high rank coal exhibit an increase and followed by a decrease with increasing R o,max values, while the average pore diameter and permeability demonstrate a decrease and followed by an increase with R o,max . Although there are some variations in the results of MIP and LT-N 2 A analysis for different pore size ranges, the overall findings suggest that ultrasonic stimulation in conjunction with CFF effectively alters the coal pore structure. The most significant improvement was observed in coking coal, where pore volume increased by 22%, pore area decreased by 11% and tortuosity decreased by 47%. The improvement of lean coal is the smallest, the pore volume increases by about 7%, and the surface area decreases by about 14%. It is found that the modification of coal pore volume is mainly concentrated in transition pores and macropores. These research outcomes provide valuable insights into the application of ultrasonic technology in coalbed gas extraction.
Introduction
In the future, coal will remain the main energy source for many countries, such as China and India. Coalbed methane (CBM) can induce coal and gas outbursts, and other disasters, which restricts the high-efficient mining of coal 1 , 2 , 3 . CBM is a kind of clean energy source, and its direct emission will also aggravate the greenhouse effect 4 , 5 . Therefore, mining CBM can reduce coal mine accidents, increase energy supply and help achieve carbon peaking 6 , 7 .
In the last 20 years, water jet cutting technology, water jet perforation technology, hydraulic fracturing technology, and other technologies have emerged one after another and have become the main technologies to enhance CBM extraction 8 , 9 , 10 . Among them, the application effect of hydraulic fracturing is more prominent, and it has been applied in most highly gassy mine in China 11 . To further improve the effectiveness of hydraulic fracturing technology, many new hydraulic fracturing technologies were proposed 12 , 13 , 14 , such as pulse fracturing 15 , tree-type fracturing 16 , and the fracturing pressure, fracturing range, and extraction effect also researched 17 , 18 , 19 . These research results have more or less promoted the development of hydraulic fracturing technology. In addition to optimizing fracturing technology, improving fracturing fluid is also an important means to improve hydraulic fracturing 20 , 21 , 22 , 23 , such as CFF, foam fracturing fluid, guar gum fracturing fluid and so on. Among them, CFF is one of the fracturing fluids with better application effect 24 . The research 25 shows that the fracturing fluid has stronger fracturing ability, can form wider and more complex hydraulic fractures, and is conducive to CBM extraction. Fracturing fluid will also produce physicochemical reactions with minerals in coal, increase the pore structure and average pore diameter of coal. Zhou et al. 26 found that CFF has a better wetting effect, can also reduce the functional groups, reduce the ash content, and increase the calorific value of coal combustion. Xue et al. 27 compared the effects of Slickwater, Guar gel and VES fracturing fluid on the shape and fractal dimension of coal pores, and the effect of VES clean fracturing fluid was the most significant. Huang et al. 28 compared different fracturing fluids on gas flow, and found that compared with foam fracturing fluid, water-based fracturing fluid gels have adverse effects on the permeability of gas. Ge et al. 29 studied the impact of different types of fracturing fluids on pore volume and connectivity, and compared the effects by combining the changes in pore volume of different pore.
In addition, changing the external physical field can also promote the extraction of CBM, such as ultrasonic 30 , 31 , high-voltage electricity 23 , 32 and so on. Among them, the study on the use of ultrasonic to enhance CBM has been carried out for many years, and its application potential is huge 33 . Scholars have also researched the use of ultrasonic to stimulate coal seam fracturing and promote gas desorption and flow 34 , 35 . Scholars such as Liu 36 and Tang 37 found that ultrasound can improve the shape and size of pores, expand the original cracks in coal seam and increase their connectivity, thus improving the permeability. Jiang et al. 38 also confirmed the influence of ultrasonic on fracture width and permeability through numerical simulation, and found that coal body properties and ultrasonic incident angle are the main factors affecting the effect of ultrasonic on increasing coal seam permeability. Jiang et al. 39 studied the effect of ultrasonic on the desorption rate and desorption amount of coalbed methane, and also established a model of CBM desorption under the action of ultrasonic according to the experimental results. Liu et al. 40 studied the gas adsorption and diffusion of coal samples with different water content after ultrasonic stimulation, and found that the gas adsorption and diffusion coefficient increased significantly after ultrasonic stimulation, and the higher the water content, the more obvious.
Zuo et al. combined the advantages of the above technologies to propose a new technology of ultrasonic and hydraulic fracturing to increase the permeability and gas extraction effect 41 . The research found that the fracturing fluid and ultrasonic can significantly improve the modification effect of coal seam, the ultrasonic power and temperature will also affect the modification effect 42 . As shown in Fig. 1 , the thermal, cavitation, mechanical and chemical effects of ultrasonic waves can induce the extension direction of fractures, accelerate the reaction rate between coal and CFF, clear the extraction channel, promote the desorption and flow of CBM, and finally enhance the gas extraction effect. However, the applicability of this technology to different coal ranks is still unclear. Therefore, this paper carries out an immersion test of different coal samples affected by ultrasonic, and analyzes the changes of coal pore structure after treated by CFF. The research conclusions can expand the theory and technology of CBM mining and promote the development of ultrasonic assisted hydraulic fracturing technology.

Principle diagram of ultrasonic assisted hydraulic fracturing.
Experimental design
Samples preparation.
Four samples of different coal ranks were obtained from four mines in Guizhou and Yunnan, China. The basic parameters were determined, as shown in Table 1 . According to the China National Standards: Chinese classification of in seam coal (GB/T 17607-1998), the DH, WJ, and TC are medium-rank coal, and BL is high-rank coal.
Experimental process
The coal samples were immersed in a high-pressure sealed tank for a duration of 4 h, the immersion pressure was 1.0 MPa, as shown in Fig. 2 . The experimental temperature was maintained at a constant 40 °C. The ultrasonic parameters during the immersion process were set at 40 kHz with a total power of 1 kW. CFF was employed for the experiment, consisting of a mixture of 0.2 wt% Nasal, 0.8 wt% CTAC, and 1 wt% KCl. Preliminary experiments have indicated that this CFF can undergo chemical reactions with coal, and ultrasonic waves can significantly enhance the rate of these chemical reactions, thereby substantially improving the micro-pore structure of coal.

Flow chart of the experiment (the map from the Map Technology Review Center, Department of Natural Resources; http://bzdt.ch.mnr.gov.cn/browse.html?picId=%224o28b0625501ad13015501ad2bfc0280%22 ).
Testing methods
To assess the influence of ultrasonic-assisted CFF on coal samples of varying degrees of metamorphism, MIP and LT-N 2 A were chosen to analyze the changes in coal sample pore structure before and after the treatment.
Experimental results
Mip analysis.
The MIP curves for the four coal samples are depicted in Fig. 3 . Among them, the TC coal sample exhibits the highest pore volume, while the WJ sample shows the lowest, corresponding to the variations in porosity. It is evident that after the application of ultrasonic-assisted CFF, the MIP curves of the coal samples demonstrate varying degrees of alteration, with increased pore volumes observed across all coal ranks. This suggests that ultrasonic-assisted fracturing technology enhances permeability in different medium-ranked coals, although the extent of improvement varies. Furthermore, the efficiency of mercury withdrawal differs before and after the treatment. After the application of ultrasonic-assisted CFF, the mercury withdrawal rates for all coal samples increase, indicating improved pore connectivity and a reduction in the proportion of closed pores. Compared to the raw coal samples, ultrasonic-assisted CFF widens pore fractures, connects some closed pores, and reduces the complexity of pore throat structures, thereby facilitating the removal of mercury from closed pores during withdrawal.

The MIP curves of different coal samples. ( a ) The DH coal sample; ( b ) The WJ coal sample; ( c ) The TC coal sample; ( d ) The BL coal sample.
Intrusion volume
According to Hodott's aperture classification standard, pores with diameters less than 10 nm are referred to as micropores, pores ranging from 10 to 100 nm are termed transition pores, pores between 100 and 1000 nm are considered mesopores, and pores larger than 1000 nm are classified as macropores. Figure 4 presents the pore volume distribution curves and the distribution percentages of different pore sizes, respectively. The DH, TC, and BL coal samples exhibit similar pore size distributions, primarily consisting of transition pores and macropores, with fewer mesopores. In contrast, the lower-ranked WJ coal sample primarily consists of transition pores, with fewer macropores and mesopores. Notably, after the application of CFF, the different coal ranks show variations in the distribution of pore size categories: (a) For the DH coal sample, the percentage of pore volume in different pore sizes remains basically unchanged after the experiment, but the overall volume increases from 0.036 to 0.041 mL/g, a 13% increase. The volumes of micropores, transition pores, and macropores increase, while the volume of mesopores decreases, particularly for pores smaller than 20 nm and larger than 10,000 nm. Mid-sized pores show a decrease. This is primarily because the interaction of CFF with the coal widens existing pores to varying degrees, increasing their sizes, with fewer new micropores generated. (b) In the case of the WJ coal sample, there is a slight increase in transition pores after the experiment, while the distribution percentages of other pore sizes remain relatively stable. However, the overall volume increases from 0.029 to 0.032 mL/g, approximately a 14% increase. This suggests that some micropores in the coal sample have transformed into transition pores during the process. (c) For the TC coal sample, the volume increased from 0.054 to 0.066 mL/g after the experiment, a 22% increase, indicating that the interaction between CFF and TC coal is the most effective. The changes in the pore volumes of micropores and transition pores are particularly pronounced. Treated with ultrasonic-assisted CFF, the number of micropores decreases, while the number of transition pores increases, with little change in mesopores and macropores. This is primarily because the TC coal sample has the highest number of micropores, providing the largest contact area between CFF and coal, which facilitates the reaction and significantly alters the micropore sizes. Additionally, since transition pores range from 10 to 100 nm, under the same conditions, micropores are more likely to transform into transition pores. (d) The BL coal sample exhibits similarities to the TC coal sample, with a decrease in micropores and mesopores and a slight increase in transition pores and macropores. However, the total pore volume for the BL coal sample increases from 0.030 to 0.032 mL/g, representing an approximately 7% increase. This suggests that the interaction between CFF and the BL coal sample is less effective, mainly because the micropores are widened into transition pores, and relatively few new micropores are generated.

The pore volume distribution curves and percentages of different pore sizes. ( a ) The pore volume distribution curves; ( b ) The percentages of different pore sizes.
It can also be found that, affected by the properties of specific surface area, the pore surface area (PSA) of coal samples of different coal ranks is principally micropores and transition pores, for about 98%. The PSA of DH, WJ, and BL coal samples are relatively small, while that of TC coal samples is larger. In Fig. 5 , the PSA of DH and WJ coal samples increased after treated by ultrasonic assisted CFF, while the PSA of TC and BL samples decreased after the action of CFF. (a) For DH coal samples, after the experiment, the total PSA increased from 4.2 to 5.5 m 2 /g, an increase of about 30%, but the proportion of PSA of different pore sizes remained basically unchanged, which meant that the PSA of micropores and transition pores increased. Combined with the changes in the number of pore volumes, the pore size of the coal sample becomes larger after treated by CFF, and the micropores become transition pores. Besides, a small number of new micropores will be generated, ultimately resulting in an increase in the PSA of both micropores and transition pores with unchanged distribution percentages. (b) For the WJ coal sample, the total PSA increased from 5.6 to 6.3 m 2 /g after the experiment, an increase of about 13%. Specifically, the PSA of micropores changed a little, the PSA of transition pores increased, and the proportion of PSA increased by about 5%, indicating that new micropores were generated when the original micropores became transition pores in the WJ coal. (c) For TC coal, the total PSA decreased from 11.6 to 10.3 m 2 /g after the experiment, with a reduction of about 11%. The PSA of micropores decreased from 8.0 to 4.9 m 2 /g, and the PSA of transition pores increased from 3.6 to 5.3 m 2 /g, indicating that relatively few new micropores were generated after the interaction of CFF and TC coal. The possible reason is that there are many micropores in TC coal, and the contact area between CFF and coal is the largest, which is conducive to chemical reaction between CFF and coal. Finally, during the immersion process, CFF will chemically react with minerals around the micropores and expand the pores to become transition pores, without generating too many new micropores. It is also possible that there is less mineral content in the coal, making it difficult for the CFF to react with the coal. (d) Similar to the TC coal, the BL coal sample exhibits a decrease in the PSA of micropores and an increase in the PSA of transition pores after the experiment. The total PSA for the BL coal sample decreases from 4.5 to 3.9 m 2 /g, indicating a roughly 14% decrease. The PSA of micropores decreases from 2.9 to 2.0 m 2 /g, while the PSA of transition pores increases from 1.5 to 1.8 m 2 /g. This is also attributed to the limited generation of new micropores.

The pore area distribution curves and percentages of different pore sizes. ( a ) The pore area distribution curves; ( b ) The percentages of different pore sizes.
- Fractal dimension
The fractal dimension can characterize the uniformity coefficient of coal seam pore structures. A smaller fractal dimension indicates a more uniform distribution of reservoir pore throats and stronger homogeneity. The fractal dimension of porous rocks typically falls between 2 and 3. The Menger model 43 is used to analyze the fractal dimension of pores. The relationship between \(dV_{P}\) and \(dP\) is expressed by Eq. ( 1 ).
where V P is the cumulative mercury intake when the mercury intake pressure is P , D = A + 4, A is the slope of Eq. ( 1 ), D is the fractal dimension, and the larger D is, the stronger the pore heterogeneity is.
To get the average fractal dimension ( D T ) with data divided into micropores (< 100 nm), mesopores (100–1000 nm), and macropores (> 1000 nm) according to the aperture size 44 , and the fractal dimensions D 1 , D 2 , and D 3 were calculated respectively. Then D T can be calculated as Eq. ( 2 ).
where \(\varphi_{1}\) , \(\varphi_{2}\) , and \(\varphi_{3}\) is the proportion of pore volume of micropores (< 100 nm), mesopores (100–1000 nm), and macropores (> 1000 nm), respectively.
The D 1 , D 2 , and D 3 can be obtained by piecewise fitting of the \(dV_{P}\) and \(dP\) data, as shown in Fig. 6 .
Macropores: The fractal dimensions of DH, WJ, and BL coal samples all decreased after treated by CFF, with a reduction of approximately 11%. This suggests that the pore structure became simpler, and pore homogeneity increased. Combined with Fig. 4 , it can be seen that after treated by CFF, the pore volume of macropores becomes larger, that is, the pore diameter becomes larger. Additionally, any protruding particles within the pores were eliminated, resulting in reduced pore tortuosity. Only the fractal dimension of TC increased after the treatment, with an increase of about 15%. Combined with Fig. 4 , the pore volume of macropores is basically unchanged after CFF action, indicating that CFF action has little influence on macropores.
Mesopores: In contrast to macropores, the fractal dimensions of DH, WJ, and BL all increased by approximately 5% after the CFF treatment, while the fractal dimension of TC coal decreased by about 5%. Combined with the changes in the pore volume after treated by CFF in Fig. 4 , only the pore volume of TC coal sample increases, and the pore structure becomes simple.
Micropores: The fractal dimensions of DH and WJ coal samples increased by 7% and 1% after the CFF treatment, respectively. While the fractal dimensions of TC and BL decreased by 15% and 3%, respectively. Combined with Fig. 4 , it is found that the transition pores volume increases after CFF action, while the pore volume decreases in TC and BL coal samples and increases in DH and WJ coal samples after CFF action This indicates that micropores play a crucial role in determining the fractal dimension within this size range, primarily because micropores have smaller diameters, making them more sensitive to changes in pore shape.

Fractal dimension of coal samples. ( a ) The DH coal sample; ( b ) The WJ coal sample; ( c ) The TC coal sample; ( d ) The BL coal sample.
Figure 7 shows the LT-N 2 adsorption and desorption curves of four coal samples of different ranks before and after CFF action. The adsorption and desorption curves of different raw coal samples are basically similar. Among them, DH, TC, and BL exhibit relatively small hysteresis loops, while the hysteresis loop in WJ is not very pronounced. In the nitrogen adsorption curve, when the relative pressure is less than 0.9, the N 2 adsorption amount increases relaxedly with the increase of the relative pressure. When the relative pressure is greater than 0.9, the adsorption amount of N 2 increases rapidly. After treated by CFF, all coal samples exhibit varying degrees of hysteresis loops. Among them, the DH-treated coal sample has the most pronounced hysteresis loop, with the most significant changes occurring around a relative pressure of 0.5. This suggests that the morphological structure of the pores has changed. In addition, the volume of nitrogen adsorbed by different treated coals also changes to different degrees, indicating that the size and quantity of pores have changed.

LT-N 2 adsorption and desorption curves.
Pore morphology
The maximum nitrogen adsorption capacity of different raw coal samples does not vary significantly, but it increases to different degrees after the combined action of ultrasonic-assisted CFF. Among the raw coal samples, the TC coal exhibited the highest N 2 adsorption capacity, while the DH coal showed the most significant increase after ultrasonic-assisted CFF treatment. The maximum nitrogen adsorption capacities for the DH, WJ, TC, and BL coal samples were 3.18 cm 3 /g, 3.36 cm 3 /g, 5.22 cm 3 /g, and 3.65 cm 3 /g, respectively. After the treatment with ultrasonic-assisted CFF, these capacities increased by 52.3%, 35.9%, 27.6%, and 14.3%, respectively. The number, size, and shape of pores are the dominant factors influencing nitrogen adsorption capacity. As coal rank increases, the rate of increase in maximum nitrogen adsorption capacity gradually decreases. This is primarily because higher-ranked coals typically have fewer mineral impurities, which reduces the efficacy of the reaction between CFF and the coal, limiting effective pore modification.
The adsorption and desorption curves provide insight into the morphology and quantity of micropores. It is observed that there is no coincidence between desorption and adsorption curves across the full pore size range of different coal samples, with the extent of the difference varying. The primary reason for this is capillary condensation of N 2 in larger pores, leading to the formation of "hysteresis loops" of varying degrees. These hysteresis loops indicate the presence of micropores, especially at lower relative pressures, where significant adsorption hysteresis occurs. Notably, the desorption and adsorption curves for the DH-treated and WJ-treated coal samples exhibit a large gap, with pronounced hysteresis loops, indicating a relatively strong chemical reaction between CFF and coal. The pores formed in these samples are primarily open, with many micropores and a significant number of slit or parallel plate pores. In contrast, other coal samples, particularly the raw ones, exhibit smaller hysteresis loops, suggesting fewer slit or parallel plate pores and more poorly connected pores (such as wedge-shaped, conical, or cylindrical pores).
It is worth mentioning that inflection points appear near a relative pressure of 0.5, with the inflection point being most pronounced in the DH-treated coal sample and least in the WJ coal sample. This indicates varying numbers of ink-bottle-shaped pores in the samples. The specific reason for this is that the desorption rate of nitrogen slows at the bottleneck of ink-bottle-shaped pores. As the relative pressure decreases and the bottleneck is overcome, the desorption rate accelerates, causing the condensed liquid N 2 in these pores to gush out rapidly, resulting in a steep decline in the desorption curve and forming an inflection point. Mineral impurities in coal generally exist as particles or layers and are connected with the original natural pores. When CFF reacts with these mineral impurities, it likely erodes the coal through the original natural pores, forming ink-bottle-shaped pores deep within the coal. Additionally, when the relative pressure approaches 1, the adsorption curve rises sharply and partially coincides with the desorption curve. This phenomenon is due to multimolecular layer adsorption in large pores within the coal, where the interaction between N 2 molecules and the pore surface area (PSA) is relatively weak.
The fractal dimension
To further analyze the pore structure, the fractal dimension D of the pore was calculated using the Frenkel-Halsey-Hill (FHH) model 45 , as shown in Eq. ( 3 ). The specific results are shown in Fig. 8 . Due to the existence of many ink-bottle shaped pores in the coal sample, an inflexion point appeared on the desorption curve. The fractal dimension calculated in sections can get accurate results. When the relative pressure is larger than 0.5, the fractal dimension is D 1 , and when the relative pressure is less than 0.5, the fractal dimension is D 2 . When the relative pressure is 0.5, the corresponding aperture is about 4.5 nm. The aperture measured by fractal dimension D 1 is in the range of 4.5–100 nm, and the aperture measured by fractal dimension D 2 is in the range of 2.0–4.5 nm.
where P 0 is the gas-saturated vapor pressure of N 2 , MPa; P is the actual pressure, MPa; V is the corresponding N 2 adsorption capacity, mL/g; V 0 is the monolayer volume of N 2 adsorption at standard temperature and pressure (ml/g); C is the constant; and A is the slope of the fitted curve. So the fractal dimension is A + 3. The fractal dimension always between 2 and 3, and the closer it is to 2, the smoother the pores.

The fractal dimension fitting results.
It can be observed that the fractal dimension D 1 is approximately around 2.5 when the relative pressure exceeds 0.5, while D 2 is generally less than 2 when the relative pressure is less than 0.5. When ultrasonic and CFF works together, the fractal dimension D 1 shows a small increase with relatively minor changes. In contrast, D 2 exhibits varying changes, with some increasing and others decreasing. Moreover, except for WJ coal, D 2 of other treated coal was closer to 2.
Based on the principles of LT-N 2 A, when the relative pressure is less than 0.5, smaller pores are measured, otherwise is larger pores are measured. The relatively minor changes in fractal dimension D 1 and the more substantial changes in fractal dimension D 2 imply that the combined effect of ultrasonic and CFF treatment has a more pronounced impact on smaller pores and a less significant effect on larger pores. This is primarily due to the reactions between the CFF and coal, which results in the disappearance of mineral particles around smaller pores. The same mineral particles have a more significant impact on smaller pores, result in the greater variations in fractal dimension D 2 .
To analyze the changes in pore structure across different coal ranks after treatment with ultrasonic-assisted CFF, SEM was used to observe the coal samples before and after treatment. Figure 9 shows the specific scanning results. It is evident that the mineral particles attached to the coal of different ranks are significantly reduced after treatment. This reduction occurs because the mechanical vibrations from the ultrasound generate shear and tensile stresses, causing the attached mineral particles to detach from the coal sample surface. Additionally, the acid in the fracturing fluid chemically reacts with the mineral particles, dissolving them within the CFF. Regarding the pore morphology on the sample surfaces, slight differences are observed across the various coal ranks, primarily reflected in surface roughness and the presence of micropores. The SEM images reveal noticeable differences in the number and size of pores, indicating the creation of many new micron-scale pores. These microscale pores often develop from nanoscale pores, suggesting that new nanoscale pores are also generated during processing. Overall, the surfaces of the TC and BL coal samples appear smoother, while the surfaces of the WJ and TC coal samples show slightly more porosity. This difference is primarily due to the coal becoming denser and more brittle during the metamorphism process, making it easier to form a flat section during crushing. After treatment with ultrasonic-assisted CFF, the surfaces of all coal samples became smoother, with some of the original small undulations disappearing. These changes result from the chemical reaction between the CFF and the coal, combined with the surface washing effect of the ultrasound.

SEM photos of different coal samples.
Variation rules of pore parameters
With the increase of the coal metamorphism degree, the total pore volume and total PSA both increase first and then decrease, and the peak value occurs when coking coal ( R o,max is 1.5), and the pore volume and total PSA are the largest. As shown in Fig. 10 , the average pore diameter and permeability showed a trend of decreasing first and then increasing, and both showed a trough value when coking coal ( R o,max is 1.5). This is mainly because the porosity of coal is affected by the degree of metamorphism, and the porosity will first decrease and then rise as the metamorphism degree increase. This is mainly because in the process of metamorphism, affected by temperature and geological conditions, the molecular structure of coal has changed, resulting in changes in the porosity of coal. After treated by ultrasonic and CFF, the total pore volume and total PSA still increase first and then decrease, and the peak value appears when coking coal ( R o,max is 1.5). The average pore diameter and permeability still showed a trend of decrease first and then increase, but the valley value appeared in the fat coal ( R o,max is 1.1). The reason for this phenomenon is that TC coal sample has the most pronounced response to CFF, which has a great influence on pore diameter and permeability.

Variation rules of pore parameters by MIP data.
Mercury withdrawal efficiency and tortuosity are also parameters used to assess coal seam pore structure and gas flow efficiency. The higher mercury withdrawal efficiency, the less proportion of closed holes and the more proportion of open holes in the coal sample, the more helpful the gas desorption and flow. The greater the tortuosity of cracks, the greater the gas flow resistance. For the raw coal in Fig. 11 , both mercury withdrawal efficiency and tortuosity show an initial increase followed by a decrease when metamorphism degree increase. The tortuosity is the largest when it is coking coal ( R o,max is 1.5), and the mercury withdrawal efficiency is the highest when it is fat coal ( R o,max is 1.1). After the combined treatment of ultrasonic and CFF, the trends for mercury withdrawal efficiency and tortuosity remain consistent. However, the peak of mercury withdrawal efficiency is observed at the coke coal ( R o,max is 1.5), while tortuosity reaches its maximum at the fat coal ( R o,max is 1.1). Besides, the average fractal dimension increases first, then decreases and then increases, and the minimum value appears in coking coal ( R o,max is 1.5).

Variation rules of pore structure by MIP data.
We also analyzed the variation trend of LT-N 2 A results with coal rank, which show some differences compared to the MIP results, as detailed in Fig. 12 . It can be found that with the increase of metamorphism degree, the N 2 adsorption capacity of the raw coal shows a trend of first increasing and then decreasing, and the peak value appears when it is coking coal ( R o,max is 1.5). The average pore diameter also shows the same trend, and also appears the maximum value at coking coal ( R o,max is 1.5). These changes are related to the coal metamorphism degree, as the pore distribution and porosity of coal continuously change during the coal's metamorphic process. After combined treatment of ultrasonic and CFF, the adsorption amount of N 2 increases in all coal rank samples, and the average size of pore shows both decreases and increases. The main reason is that the pore structure and mineral impurities of different coal samples are different, and the effect of CFF is also different. Only the BL treated coal samples show a significant increase in the average pore size, with an increase of approximately 18%, while the average pore size of the other samples remains relatively unchanged. The primary reason is that the CFF changes the natural pore diameter, but also produces new small pores, so the average pore diameter does not have a big change. Combined with MIP data, it can be found that due to the development of pore structure of BL coal sample, it is more conducive to chemical reaction with CFF, so the pore volume and average pore diameter change greatly.

Variation rules of pore structure by LT-N 2 A data.
Furthermore, the changes in fractal dimensions D 1 and D 2 for different pore size ranges exhibit distinct trends, with D 2 showing significantly larger variations compared to D 1 . The D 1 of raw coal and treated coal decreased first and then increased as the metamorphism degree increase, and the variation of D 1 after the action of CFF was small, about 2% on average. The D 2 of raw coal samples exhibits a trend of increasing first and then decreasing, while for treated coal samples, D 2 shows a pattern of decreasing initially, then increasing, and finally decreasing again with increasing metamorphism degree. It's notable that DH and WJ coal samples exhibit relatively large changes in D 2 after CFF treatment, with variations of 33% and 18%, respectively. This is because, with the increase in coal metamorphism, the micropore structure in the smaller pore sections becomes more complex and is more susceptible to significant changes after the action of CFF. In contrast, larger pores are less affected by CFF and are less likely to undergo substantial changes. Additionally, differences were observed in the trends of fractal dimensions obtained from MIP and LT-N 2 A. We believe there are three main reasons for these differences. First, MIP and LT-N 2 A are based on different testing principles, and the high pressure used in MIP can damage the pores, leading to inaccuracies in the results. Second, MIP targets pores within the size range of 5 to 340,000 nm, while LT-N 2 A focuses on pores ranging from 2 to 500 nm. The differences in the targeted pore sizes between these two methods contribute to the variations in fractal dimension trends. Third, CFF has a significant influence on micropores and transition pores, leading to substantial changes in fractal dimensions and pore volume in these regions. These factors collectively result in the differing fractal dimension trends observed.
The reasons and forms of pore changes
Coal is a mixture containing various mineral impurities, including Montmorillonite ((Na,Ca) 0.33 (Al,Mg) 2 [Si 4 O 10 ](OH) 2 ·nH 2 O), Calcite (CaCO 3 ), Kaolinite (Al[Si 4 O 10 ](OH) 8 ), Dolomite (CaMg(CO 3 ) 2 ), Fe 2 O 3 , and other minerals that are randomly distributed within coal seams. The CFF NaSal undergoes ionization to produce H + , as represented by the possible ionization Eq. ( 4 ). H + then react chemically with minerals such as Calcite (CaCO 3 ), Kaolinite (Al[Si 4 O 10 ](OH) 8 ), Fe 2 O 3 , and other minerals. The four samples belong to different coal ranks, and the mineral impurities contained in them will be different. The possible chemical equations for these reactions are presented in Eqs. ( 5 )–( 14 ).
During the chemical reactions between CFF and mineral impurities within coal, the effectiveness of these reactions depends on the degree of contact between the CFF and the minerals. The more extensive the contact, the more active the CFF molecules become, resulting in better chemical reaction outcomes. In the case of TC coal samples, the change in pore volume is most significant and evident. Mainly because the TC coal sample has the largest surface area, it can ensure that the CFF is in full contact with mineral impurities, increasing the possibility of chemical reactions. Additionally, under normal conditions, chemical reactions can lead to concentration gradients and steric hindrance, resulting in a gradual decrease in the chemical reaction rate. However, ultrasonic can accelerate the activity of chemical molecules in the CFF, effectively promoting and enhancing the progress of these reactions 46 , 47 .

CFF and coal undergo physical or chemical reactions that can have four key effects on coal samples, as illustrated in Fig. 13 : (a) New Pore Formation: CFF interacts with coal, eroding and damaging the coal sample, leading to the creation of micropores or small pores on the coal’s surface. The location of these newly formed pores is random but generally influenced by the positions of mineral particles on the coal surface. While a significant number of new pores are generated, their small size does not notably impact the overall pore volume but does increase the coal sample’s specific surface area (PSA), particularly for small pores. (b) Pore Enlargement: CFF may penetrate pre-existing pores in the coal, where it undergoes physical and chemical reactions with the surrounding mineral particles, thereby enlarging these pores. Typically, the number of small pores increases the most, while the number of medium and large pores increases less. This is primarily determined by the distribution of pore numbers and the classification of pore sizes. Since micropores are the most abundant in coal samples, and because the size intervals of micropores (< 10 nm) and transition pores (10–100 nm) are similar, micropores are more likely to transform into transition pores. (c) Pore Connectivity: The chemical reaction between CFF and the coal sample may widen and connect multiple pores, leading to the formation of new, larger pores. Additionally, the pressure exerted by CFF within the pores can cause the coal sample’s pores to break through barriers with previously closed pores, allowing access to these closed pores during the expansion process, thus forming new and larger pores. This process significantly increases pore size and may also impact the tortuosity of the pores. (d) Dissolution: As CFF enters the pores, attached particles within the pores may restrict its flow, reducing the permeability of the coal. The flow of CFF scours these attached particles, accelerates the physicochemical reactions between CFF and the particles, and smoothens the pores, thereby reducing their tortuosity.

The possible four effects on coal samples.
The rate of interaction between the coal sample and the CFF depends on the concentration of the CFF and the contact area between the CFF and the coal sample (the surface area of the coal sample). When the concentration of CFF remains constant, a larger coal sample surface area ensures more extensive contact between the CFF and the coal, resulting in more chemical reactions and improved treatment effectiveness. This lead to the pore volume and mercury withdrawal efficiency of TC coal increase the most.
Under the action of ultrasonic stimulation, the CFF can effectively modify the micropore structure. In this paper, the modification effect of coal pore structure of different ranks was analyzed by MIP and LT-N 2 A. The conclusions as bellow:
The original pore parameters and pore complexity of coal samples differ across various coal ranks. In medium to high-rank coals, pore volume and surface area show an initial increase followed by a decrease trend with respect to R o,max , where coking coal exhibits relatively higher pore volume and surface area. Conversely, the average pore size and permeability decreased first and then increased with R o,max , with fat coal having a relatively smaller average pore diameter and permeability.
Based on the data obtained from MIP, the pore volume of coal from different ranks increased after modification. However, the surface area from various ranks exhibited different degrees of increase or decrease. This is mainly due to the changes in the average pore diameter resulting from the modification by CFF under the influence of ultrasonic waves. Overall, the modification of coking coal by CFF under the influence of ultrasonic waves is the most significant.
According to the LT-N 2 A results, the gas adsorption capacity of different coal ranks significantly increased after modification under the influence of ultrasonic waves, with coking coal exhibiting a relatively large increase in average pore diameter (approximately 18%). The different effects on the pores also lead to distinct trends in the changes of fractal dimensions D 1 and D 2 in various pore size ranges.
CFF will chemically react with coal, which may have the following effects on coal samples: CFF will erode coal and form new pore on the coal surface; CFF enters the pores in the coal sample and enlarges the pore size; CFF connects multiple pores to form new large pores; CFF dissolves attached mineral particles on the coal surface.
Data availability
The datasets used and analysed during the current study available from the corresponding author on reasonable request.
Checko, J., Urych, T., Magdziarczyk, M. & Smolinski, A. Research on the processes of injecting CO 2 into coal seams with CH 4 recovery using horizontal wells. Energies https://doi.org/10.3390/en13020416 (2020).
Article Google Scholar
Liu, P., Fan, J. Y., Jiang, D. Y. & Li, J. J. Evaluation of underground coal gas drainage performance: Mine site measurements and parametric sensitivity analysis. Process Saf. Environ. Prot. 148 , 711–723. https://doi.org/10.1016/j.psep.2021.01.054 (2021).
Article CAS Google Scholar
Okere, C. J. et al. Experimental, algorithmic, and theoretical analyses for selecting an optimal laboratory method to evaluate working fluid damage in coal bed methane reservoirs. Fuel https://doi.org/10.1016/j.fuel.2020.118513 (2020).
Lekontsev, Y. M., Sazhin, P. V., Novik, A. V. & Mezentsev, Y. B. Methane production rate in hydraulic fracturing of coal seams. J. Min. Sci. 57 , 595–600. https://doi.org/10.1134/S1062739121040062 (2021).
Zou, Q. L., Liu, H., Jiang, Z. B. & Wu, X. Gas flow laws in coal subjected to hydraulic slotting and a prediction model for its permeability-enhancing effect. Energy Source Part A https://doi.org/10.1080/15567036.2021.1936692 (2021).
Lloyd, M. K. et al. Methoxyl stable isotopic constraints on the origins and limits of coal-bed methane. Science 374 , 894. https://doi.org/10.1126/science.abg0241 (2021).
Article ADS CAS PubMed Google Scholar
Serdyukov, S. V., Kurlenya, M. V., Rybalkin, L. A. & Shilova, T. V. Hydraulic fracturing effect on filtration resistance in gas drainage hole area in coal. J. Min. Sci. 55 , 175–184. https://doi.org/10.1134/S1062739119025432 (2019).
Lu, Y. Y., Ge, Z. L., Yang, F., Xia, B. W. & Tang, J. R. Progress on the hydraulic measures for grid slotting and fracking to enhance coal seam permeability. Int. J. Min. Sci. Technol. 27 , 867–871. https://doi.org/10.1016/j.ijmst.2017.07.011 (2017).
Zuo, S. J., Peng, S. Q., Zhou, D. P., Wang, C. W. & Zhang, L. An analytical model of the initiation pressure for multilayer tree-type hydraulic fracturing in gas-bearing coal seams. Geomech. Geophys. Geo https://doi.org/10.1007/s40948-022-00509-9 (2022).
Zuo, S. J., Zhang, L. & Deng, K. Experimental study on gas adsorption and drainage of gas-bearing coal subjected to tree-type hydraulic fracturing. Energy Rep. 8 , 649–660. https://doi.org/10.1016/j.egyr.2021.12.003 (2022).
Li, L. W. & Wu, W. B. Variation law of roof stress and permeability enhancement effect of repeated hydraulic fracturing in low-permeability coal seam. Energy Sci. Eng. 9 , 1501–1516. https://doi.org/10.1002/ese3.909 (2021).
Lu, W. Y. & He, C. C. Numerical simulation of the fracture propagation of linear collaborative directional hydraulic fracturing controlled by pre-slotted guide and fracturing boreholes. Eng. Fract. Mech. https://doi.org/10.1016/j.engfracmech.2020.107128 (2020).
Talapatra, A., Halder, S. & Chowdhury, A. I. Enhancing coal bed methane recovery: Using injection of nitrogen and carbon dioxide mixture. Pet. Sci. Technol. 39 , 49–62. https://doi.org/10.1080/10916466.2020.1831533 (2021).
Zhong, J. Y., Ge, Z. L., Lu, Y. Y., Zhou, Z. & Zheng, J. W. New Mechanical model of slotting-directional hydraulic fracturing and experimental study for coalbed methane development. Nat. Resour. Res. 30 , 639–656. https://doi.org/10.1007/s11053-020-09736-x (2021).
Wei, C., Zhang, B., Li, S. C., Fan, Z. X. & Li, C. X. Interaction between hydraulic fracture and pre-existing fracture under pulse hydraulic fracturing. Spe. Prod. Oper. 36 , 553–571. https://doi.org/10.2118/205387-Pa (2021).
Zuo, S. J., Ge, Z. L., Deng, K., Zheng, J. W. & Wang, H. M. Fracture initiation pressure and failure modes of tree-type hydraulic fracturing in gas-bearing coal seams. J. Nat. Gas Sci. Eng. https://doi.org/10.1016/j.jngse.2020.103260 (2020).
Liu, P., Ju, Y., Feng, Z. & Mao, L. T. Characterization of hydraulic crack initiation of coal seams under the coupling effects of geostress difference and complexity of pre-existing natural fractures. Geomech. Geophys. Geo. https://doi.org/10.1007/s40948-021-00288-9 (2021).
Ren, Q. S. et al. CDEM-based simulation of the 3D propagation of hydraulic fractures in heterogeneous coalbed Methane reservoirs. Comput. Geotech. https://doi.org/10.1016/j.compgeo.2022.104992 (2022).
Zuo, S. J., Ge, Z. L., Lu, Y. Y., Cao, S. R. & Zhang, L. Analytical and experimental investigation of perforation layout parameters on hydraulic fracture propagation. J. Energ. Resour. ASME https://doi.org/10.1115/1.4047596 (2021).
Lu, Y. Y. et al. Influence of viscoelastic surfactant fracturing fluid on coal pore structure under different geothermal gradients. J. Taiwan Inst. Chem. E. 97 , 207–215. https://doi.org/10.1016/j.jtice.2019.01.024 (2019).
Meng, Y., Li, Z. P. & Lai, F. P. Evaluating the filtration property of fracturing fluid and fracture conductivity of coalbed methane wells considering the stress-sensitivity effects. J. Nat. Gas Sci. Eng. https://doi.org/10.1016/j.jngse.2020.103379 (2020).
Wang, Z. P. et al. Effects of acid-based fracturing fluids with variable hydrochloric acid contents on the microstructure of bituminous coal: An experimental study. Energy https://doi.org/10.1016/j.energy.2021.122621 (2022).
Article PubMed Google Scholar
Zhu, C. J. et al. Experimental study on the microscopic characteristics affecting methane adsorption on anthracite coal treated with high-voltage electrical pulses. Adsorpt. Sci. Technol. 36 , 170–181. https://doi.org/10.1177/0263617416686977 (2018).
Yang, F., Ge, Z. L., Zheng, J. L. & Tian, Z. Y. Viscoelastic surfactant fracturing fluid for underground hydraulic fracturing in soft coal seams. J. Pet. Sci. Eng. 169 , 646–653. https://doi.org/10.1016/j.petrol.2018.06.015 (2018).
Zhao, H. F., Liu, C. S., Xiong, Y. G., Zhen, H. B. & Li, X. J. Experimental research on hydraulic fracture propagation in group of thin coal seams. J. Nat. Gas Sci. Eng. https://doi.org/10.1016/j.jngse.2022.104614 (2022).
Zhou, G. et al. Experimental study and analysis on physicochemical properties of coal treated with clean fracturing fluid for coal seam water injection. J. Ind. Eng. Chem. 108 , 356–365. https://doi.org/10.1016/j.jiec.2022.01.012 (2022).
Xue, S., Huang, Q. M., Wang, G., Bing, W. & Li, J. Experimental study of the influence of water-based fracturing fluids on the pore structure of coal. J. Nat. Gas Sci. Eng. https://doi.org/10.1016/j.jngse.2021.103863 (2021).
Huang, Q. M., Li, M. Y., Li, J., Gui, Z. & Du, F. Comparative experimental study on the effects of water- and foam-based fracturing fluids on multiscale flow in coalbed methane. J. Nat. Gas Sci. Eng. https://doi.org/10.1016/j.jngse.2022.104648 (2022).
Ge, Z. L. et al. Effect of different types of fracturing fluid on the microstructure of anthracite: an experimental study. Energy Source Part A https://doi.org/10.1080/15567036.2021.1980635 (2021).
Sun, Y. et al. Changes of coal molecular and pore structure under ultrasonic stimulation. Energy Fuels 35 , 9847–9859. https://doi.org/10.1021/acs.energyfuels.1c00621 (2021).
Zhang, J., Luo, W., Wan, T. Y., Wang, Z. W. & Hong, T. Y. Experimental investigation of the effects of ultrasonic stimulation on adsorption, desorption and seepage characteristics of shale gas. J. Pet. Sci. Eng. https://doi.org/10.1016/j.petrol.2021.108418 (2021).
Jia, Q. F. et al. AFM characterization of physical properties in coal adsorbed with different cations induced by electric pulse fracturing. Fuel https://doi.org/10.1016/j.fuel.2022.125247 (2022).
Wang, Z. J., Xu, Y. M. & Suman, B. Research status and development trend of ultrasonic oil production technique in China. Ultrason. Sonochem. 26 , 1–8. https://doi.org/10.1016/j.ultsonch.2015.01.014 (2015).
Article CAS PubMed Google Scholar
Chen, X. X., Zhang, L. & Shen, M. L. Experimental research on desorption characteristics of gas-bearing coal subjected to mechanical vibration. Energy Explor. Exploitation 38 , 1454–1466. https://doi.org/10.1177/0144598720956286 (2020).
Peng, S. Q. et al. Research status and trend of coal and gas outburst: a literature review based on VOSviewer. Int. J. Oil Gas Coal T. 33 , 248–281. https://doi.org/10.1504/Ijogct.2023.131646 (2023).
Liu, P., Liu, A., Zhong, F. X., Jiang, Y. D. & Li, J. J. Pore/fracture structure and gas permeability alterations induced by ultrasound treatment in coal and its application to enhanced coalbed methane recovery. J. Pet. Sci. Eng. https://doi.org/10.1016/j.petrol.2021.108862 (2021).
Tang, Z. Q., Zhai, C., Zou, Q. L. & Qin, L. Changes to coal pores and fracture development by ultrasonic wave excitation using nuclear magnetic resonance. Fuel 186 , 571–578. https://doi.org/10.1016/j.fuel.2016.08.103 (2016).
Jiang, Y. P. & Xing, H. L. Numerical modelling of acoustic stimulation induced mechanical vibration enhancing coal permeability. J. Nat. Gas Sci. Eng. 36 , 786–799. https://doi.org/10.1016/j.jngse.2016.11.008 (2016).
Jiang, Y. D., Song, X., Liu, H. & Cui, Y. Z. Laboratory measurements of methane desorption on coal during acoustic stimulation. Int. J. Rock Mech. Min. Sci. 78 , 10–18. https://doi.org/10.1016/j.ijrmms.2015.04.019 (2015).
Liu, P., Fan, L., Fan, J. Y. & Zhong, F. X. Effect of water content on the induced alteration of pore morphology and gas sorption/diffusion kinetics in coal with ultrasound treatment. Fuel https://doi.org/10.1016/j.fuel.2021.121752 (2021).
Zuo, S. J. et al. Mechanism of a novel ultrasonic promoting fracturing technology in stimulating permeability and gas extraction. Energy Rep. 8 , 12776–12786. https://doi.org/10.1016/j.egyr.2022.09.132 (2022).
Zuo, S. J. et al. The effect of temperature and ultrasonic power on the microstructure evolution of coal modified by clean fracturing fluid: An experimental study. Energy https://doi.org/10.1016/j.energy.2024.132436 (2024).
Cai, Y. D., Liu, D. M., Yao, Y. B., Li, J. Q. & Liu, J. L. Fractal characteristics of coal pores based on classic geometry and thermodynamics models. Acta Geol. Sin.-Engl. Ed. 85 , 1150–1162. https://doi.org/10.1111/j.1755-6724.2011.00247.x (2011).
Li, P., Zheng, M., Bi, H., Wu, S. T. & Wang, X. R. Pore throat structure and fractal characteristics of tight oil sandstone: A case study in the Ordos Basin, China. J. Pet. Sci. Eng. 149 , 665–674. https://doi.org/10.1016/j.petrol.2016.11.015 (2017).
Zheng, Y. F. et al. Microstructure evolution of bituminite and anthracite modified by different fracturing fluids. Energy https://doi.org/10.1016/j.energy.2022.125732 (2023).
Jung, Y., Ko, H., Jung, B. & Sung, N. Application of ultrasonic system for enhanced sewage sludge disintegration: A comparative study of single- and dual-frequency. Ksce J. Civ. Eng. 15 , 793–797. https://doi.org/10.1007/s12205-011-0832-6 (2011).
Shi, Q. M., Qin, Y., Zhou, B. Y. & Wang, X. K. Porosity changes in bituminous and anthracite coal with ultrasonic treatment. Fuel https://doi.org/10.1016/j.fuel.2019.115739 (2019).
Download references
Acknowledgements
This study was financially supported by the National Natural Science Foundation of China (No. 52304129), Guizhou Provincial Science and Technology Projects (ZK[2023] general 446, Zhi Cheng [2022] General 016). Part of this work was also jointly founded by the open project of Guizhou Provincial Double Carbon and Renewable Energy Technology Innovation Research Institute (DCRE-2023-14).
Author information
Authors and affiliations.
College of Mining, Guizhou University, Guiyang, 550025, Guizhou, China
Zuo Shaojie, Xu Zhiyuan & Ma Zhenqian
Guizhou Provincial Double Carbon and Renewable Energy Technology Innovation Research Institute, Guizhou University, Guiyang, 550025, China
Zuo Shaojie
Guizhou Energy Group Co. Ltd., Guiyang, 550025, China
Zhou Dongping
School of Mining and Mechanical Engineering, Liupanshui Normal University, Liupanshui, 550025, Guizhou, China
Liu Chengwei
Guizhou Research Institute of Oil & Gas Exploration and Development Engineering, Guiyang, 550022, Guizhou, China
Zhao Fuping
You can also search for this author in PubMed Google Scholar
Contributions
Zuo Shaojie: Writing-Original draft preparation, Conceptualization, Methodology. Xu Zhiyuan: Data curation, Software. Zhou Dongping: Visualization, Investigation. Ma Zhenqian: Writing-review and editing, Resources, Visualization, Supervision. Liu Chengwei: Supervision, Investigation. Zhao Fuping: Visualization.
Corresponding author
Correspondence to Ma Zhenqian .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/ .
Reprints and permissions
About this article
Cite this article.
Shaojie, Z., Zhiyuan, X., Dongping, Z. et al. A study on the impact of ultrasonic-stimulated clean fracturing fluid on the pore structure of medium to high rank coal. Sci Rep 14 , 21026 (2024). https://doi.org/10.1038/s41598-024-72253-x
Download citation
Received : 12 May 2024
Accepted : 05 September 2024
Published : 09 September 2024
DOI : https://doi.org/10.1038/s41598-024-72253-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Clean fracturing fluid
- Pore structure
- Coalbed gas
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Anthropocene newsletter — what matters in anthropocene research, free to your inbox weekly.

IMAGES
VIDEO
COMMENTS
Data Cleaning: Definition, Benefits, And How-To
What Is Data Cleansing? | Definition, Guide & Examples
Data cleaning (sometimes also known as data cleansing or data wrangling) is an important early step in the data analytics process. This crucial exercise, which involves preparing and validating data, usually takes place before your core analysis. Data cleaning is not just a case of removing erroneous data, although that's often part of it.
The Ultimate Guide to Data Cleaning | by Omar Elgabry
Data Cleaning: Detecting, Diagnosing, and Editing ...
Subscribe. Data cleaning, also known as data cleansing or scrubbing, is a crucial process in data science. It involves identifying and correcting errors, inconsistencies, and inaccuracies in datasets. It aims to improve data quality, ensuring it is accurate, reliable, and suitable for analysis.
Data cleaning - Better Evaluation ... Data cleaning
What does data cleaning entail? Data cleaning, also called data scrubbing or cleansing, is the practice of weeding out data within a data set that is inaccurate, repetitive, or invalid. Data cleaning is typically done manually by a data engineer or technician or automated with software.
Cleaning Data: The Basics - CBIIT - National Cancer Institute
Cleaning data means getting rid of any anomalous, incorrectly filled or otherwise "odd" results that could skew your analysis. Some examples include: Straight-lining, where the respondent has selected the first response to every question, regardless of the question. Christmas-trees, where answers have been selected to create a visual ...
Data cleaning takes place between data collection and data analyses. But you can use some methods even before collecting data. For clean data, you should start by designing measures that collect valid data. Data validation at the time of data entry or collection helps you minimize the amount of data cleaning you'll need to do.
Data Cleaning Tutorial
A COMPREHENSIVE GUIDE TO DATA CLEANING FOR ...
Data Cleaning | A Guide with Examples & Steps - Scribbr
7. Data Cleaning During the Research Data Management ...
Data cleaning is emblematic of the historical lower status of data quality issues and has long been viewed as a suspect activity, bordering on data manipulation. Armitage and Berry [ 5 ] almost apologized for inserting a short chapter on data editing in their standard textbook on statistics in medical research.
(PDF) Best Practices in Data Cleaning: A Complete Guide ...
Step 1: Identify data discrepancies using data observability tools. Step 2: Remove data discrepancies. Step 3: Standardize data formats. Step 4: Consolidate data sets. Step 5: Check data integrity. Step 6: Store data securely. Step 7: Expose data to business experts. Make quicker and better decisions from your data.
Clean data provides more accurate analytics that can be used to make informed business decisions. This, in turn, contributes to the long-term success of the business. 3. Improving Productivity. A company's contact database is one of its most valuable assets!
Data cleaning is an important data validation approach used in this study because it removes irregularities from existing data and results in a data collection that is an accurate and unique ...
Impact of Data Cleaning on Data Quality. Data cleaning is the process of identifying and solving problems, which is crucial for the management of data quality [].The lack of an effective data cleaning process may result in a "garbage in and garbage out" scenario [], adversely affecting the subsequent data analysis.In contrast, an effective data-cleaning process can transform dirty data ...
A Review on Data Cleansing Methods for Big Data
Data cleaning is a critical step in the data analysis, ensuring that data is accurate, consistent, and ready for analysis. For analysts, having access to reliable data cleaning tools can significantly streamline the data preparation process, allowing them to focus on deriving insights rather than fixing errors.
Cleaning efficacy study, for surfaces contaminated with SARS-Co-2. This dataset is associated with the following publication: Nelson, S., R. Hardison, R. Limmer, J ...
Europe's Data Centers Hub Sees Disappointing Clean-Power Auction Ireland procured 1.3 gigawatts of new wind and solar projects Results came in below the government's minimum projection
These research outcomes provide valuable insights into the application of ultrasonic technology in coalbed gas extraction. The pore structure of coal plays a key role in the effectiveness of gas ...